2010年代に入ってから、ビッグデータが多くの企業から注目されている。その理由は、ビッグデータを活用することで、同業他社との差別化を図り、売上拡大や業務効率化により企業価値を向上させることができるからである。ビッグデータを蓄積/処理する基盤としてDWH向けRDBMSやHadoopがあり、成り立ちやアーキテクチャは異なるが、データを格納して、SQLをインタフェースとしてデータにアクセスすることができる点など、利用者から見ると違いが分かり難くなってきている。そこで日本ユニシスでは、DWH向けRDBMSとHadoopを用いて、データロード、データ検索について性能面での比較検証を行い、SQL on Hadoop(Hadoop内のデータをSQLで処理する機能)の適用範囲について考察を行った。本稿では検証結果と考察を報告する。
※本稿は日本ユニシス発行の「技報通巻127号」(2016年3月発行)の記事に加筆・編集して掲載しています。
(HadoopのデータをSQLで処理する「SQL on Hadoop」の可能性[前編]からの続き)
検証結果
データロード
1TBのデータに対するHive、Verticaのデータロードの処理時間を確認する。検証手順は、表3の通りである。
 (表3)
(表3)拡大画像表示
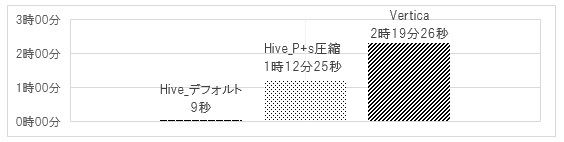
検証結果は、図5の通りである。
 (図5)
(図5)拡大画像表示
Hive_デフォルトが9秒で処理されているのは、MapR-FSのデータに対するLOAD文の実行が、内部ではファイルの移動しか行われないためである。ただし、ロードするデータがローカルディスクなどのMapR-FS以外に格納されている場合、処理時間は増加すると考える。
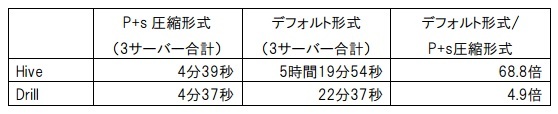
Hive_P+s圧縮の処理時間がHive_デフォルトと比べて大幅に増加(1時間12分16秒)しているのは、圧縮やフォーマット変換処理などによるものである。
Verticaはロード時にデータ圧縮処理以外にも、検索処理を効率的に行うためのプロジェクションによるデータソートや、データ格納における独自フォーマットへの変換を行っている。さらに、データ型や精度など、実データとテーブル定義との整合性もチェックするため、Hive_P+s圧縮に比べて処理時間が長いが、データを分割して各ノードで同時にロードすることで処理時間を短縮できる。これにより(仮設1)が立証されたことになる。
データ検索(グループ集計)
Hive、Drill、Verticaのデータ検索(グループ集計)の処理時間とリソース状況を確認する。また、データロードとデータ検索を合わせた処理時間を考察するために、Hive、Drillは2つのHiveテーブル形式による検証を行った。検証概要は表4の通りである。
 (表4)
(表4)拡大画像表示
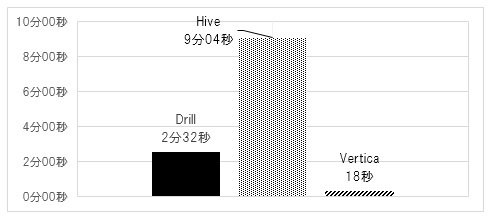
検証結果は、図6、7の通りである。まず図6で、P+s圧縮形式のHiveテーブルに対するDrill、Hiveの実行結果と、Verticaの実行結果を掲載する。また、リソース状況についても表5に掲載する。
 (図6)
(図6)拡大画像表示
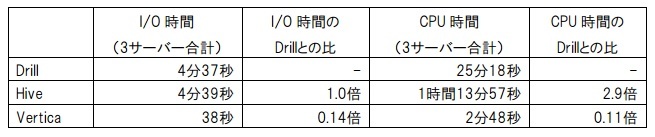 (表5)
(表5)拡大画像表示
Hive、Drill、Verticaの順に処理時間が短くなっている。HiveとDrillは、I/O時間(sarのtps×svctm×マシン数の処理時間帯での集計)は同程度であったが、CPU時間(sarのCPU使用率×マシン数×Core数の処理時間帯での集計)がHiveはDrillの2.9倍であり、それが処理時間の差となっている。Hiveはオーバーヘッドが大きいMapReduce処理を行うため、MapReduce処理を行わないDrillに比べると処理時間が長いことから、対話的ではなく、バッチ処理での適用が現実的であると考える。これにより、(仮設4)が立証されたことになる。また、Hiveのメモリ使用率が平均40%程度に対し、Drillでは平均70%程度となっており、Drillがメモリを有効に活用して処理時間の短縮を図っていることも確認できる。
VerticaはI/O、CPU時間ともにDrillより極めて少なく(I/O時間:Drillの0.14倍、CPU時間:Drillの0.11倍)、ロード時間は長いが検索時間は短いDWH向けRDBMSの特性が確認できる。
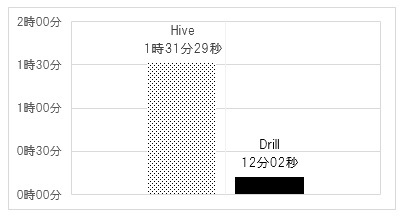
次に、図7でデフォルト形式のHiveテーブルに対するHive、Drillの結果を掲載する。また。リソース状況についても表6に掲載する。
 (図7)
(図7)拡大画像表示
 (表6)
(表6)拡大画像表示
デフォルト形式の方がP+s圧縮形式よりも大幅に処理時間が長くなっている(Hive:約10倍、Drill:約5倍)。ファイルサイズを比較するとデフォルト形式はP+s圧縮形式の約2倍(LZ4:117GB、P+s:55GB)である。しかし,P+s圧縮形式では処理対象の列だけをI/O処理するのに対し、デフォルト形式では特定の列だけでなく全列をI/O処理するため、ファイルサイズの増加以上にI/O時間が長くなっている(Hive:約69倍、Drill:約5倍)。Hiveが特に差が大きいのはMapReduce処理内でデータの読み込みだけでなく、Map処理で作成したデータを一時領域に書き込むためである。ここでも、HiveにおけるMapReduce処理の重さが確認できる。
データ検索(結合)
データ検索(結合)については、Hive、Drill、Verticaで2テーブルを内部結合する処理時間を確認する。検証概要は、表7の通りである。
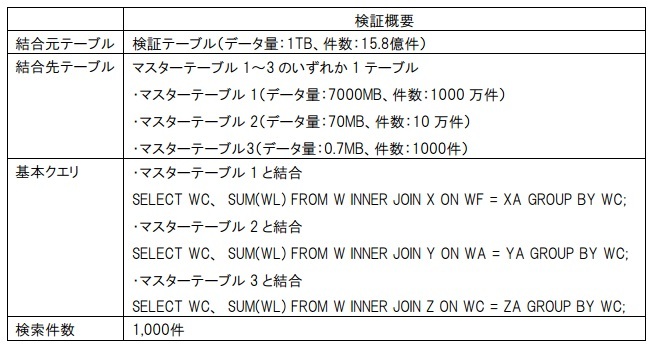 (表7)
(表7)拡大画像表示
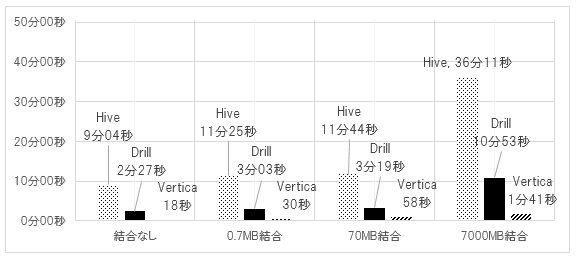
検証結果は、図8の通りである。尚、比較対象として、前節のグループ集計の結果もグラフに掲載する(結合なしのパターンが該当)。
 (図8)
(図8)拡大画像表示
Hive、Drill、Vertica全てにおいて、結合するマスターテーブルの大きさに伴い処理時間が長くなっている。Hive、Drillは、マスターテーブルが70MBと7000MBの間で処理時間に大きな差があるが、これは、Hive、Drillともにデータ量に応じて処理方式を変更しているためである。
Hiveは、テーブルのサイズが128MB以下の場合に、テーブルに対するMapReduce処理を行わず、単一マシンで処理を行うローカルモードで処理を実行する。実行計画,実行ログからも、検証テーブルは1TBのサイズなので、全ての結合ケースにおいてMapReduce処理が行われているが、マスターテーブルに対しては、0.7MB、70MBはローカルモードで処理して、7000MBのみMapReduce処理が行われている。
Drillは、マスターテーブルのレコード数が1000万件未満であれば、マスターテーブルのデータを全ノードにブロードキャスト(一斉送信)して結合処理を行うが、1000万件以上の場合は、結合キーのハッシュ値に基づき、ノード間に分散する仕組みとなっている。実行計画からも7000MBテーブル(レコード数:1000万件)の結合は分散処理が行われている。
また、Hive,Drillともに0.7MB結合と70MB結合でほとんど処理時間に差がないのは、検証用テーブルのデータ量(1TB)と比べて、マスターテーブル2(70MB)、マスターテーブル3(0.7MB)のデータ量が極めて小さいためであると考える。
Verticaは、結合するテーブルサイズによる閾値などは特になく、テーブルの大きさに応じて処理時間が増加している。