IT Leadersは2012年5月にオープンソースソフトウェア(OSS)のカオスマップ「OSS鳥瞰図」を作成・公開している。様々あり多岐にわたるOSSを鳥の目で俯瞰的に理解できるように、という意図で作成したものだ。しかしOSSの進化は急ピッチである。そこに問題意識を持った日本OSS推進フォーラム クラウド技術部会が完全リニューアルし、「OSS鳥瞰図2017年α版」を作成した。本連載はこれに基づき、主なOSSをカテゴリ毎に解説している。第6回は「ビッグデータ」カテゴリに焦点を当てる。
ビッグデータを管理/処理/分析するならOSS──事実、多くの先進企業がOSSをベースに取り組みを進めています。ビッグデータ処理に火を付けた「Hadoop」を筆頭に、この領域には多種多様のOSSが誕生し、活用範囲(できること)が広がっているのはご存じの通り。日本OSS推進フォーラムでは、もう一つ部会がこのテーマで活動しており、2016年までの活動の一部として抽出したビッグデータ関連OSSを鳥瞰図に反映しています。
ビッグデータ処理におけるカテゴリ
すでにビッグデータを活用して事業に活用している企業がある半面、多くの場合、沢山あるOSSの何を使えばいいかわからない、動きが速すぎてキャッチアップが困難など、取り組みあぐねているのも実情ではないでしょうか。ビッグデータ部会では、これらの疑問を解きほぐすための活動を行っています。
一つの成果として、データの取り込みから処理、蓄積、分析の流れを俯瞰図として示し、さらに有力なソフトウェアを抽出しマッピングしました(図1)。マッピングするOSSは毎年、コミュニティにおける開発の活性度、ソースコードの品質、開発者数、サポートの有無、書籍の数、利用実態などを考慮して選定しています。2016年度においては、米Googleが開発したディープラーニング(深層学習)のツールである「TensorFlow」の評価が高く、次いでドキュメント指向データベースの「MongoDB」という二つのOSSが飛び抜けていました。
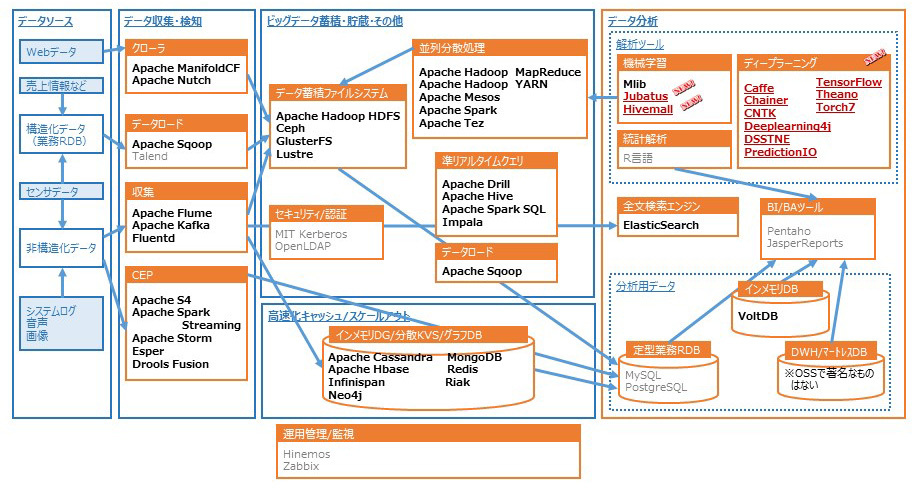 図1 ビッグデータの処理プロセスで見た主要なOSS
図1 ビッグデータの処理プロセスで見た主要なOSS拡大画像表示
図1では大きな機能ごとに下記の四つに分類しています。
- データ収集・検知
- ビッグデータ蓄積・貯蔵・その他
- 高速化キャッシュ/スケールアウト
- データ分析
なお、この分類は世界的に一般的というわけではありません。分類をまたぐ機能を備えるOSSが存在しますし、分類名に違和感を持つ読者がいるかもしません。それでも利用する立場からは、このような分類は欠かせないとビッグデータ部会では考えています。もちろん分類をどう設定するか、2017年度以降も活動の中でブラッシュアップする考えです。ここからは図1をもとに解説していきます。
会員登録(無料)が必要です


- OSSとデジタルトランスフォーメーションの関係──OSS鳥瞰図(2017/08/22)
- セキュリティ分野における注目OSSとは?─OSS鳥瞰図【第5回】(2017/06/14)
- Web/APサーバー、DBMS、開発支援ソフトウェアのOSS鳥瞰図【第4回】(2017/05/19)
- デスクトップ/業務アプリケーション、OSS鳥瞰図【第3回】(2017/04/17)
- オープンソースの運用管理ソフトウェア、OSS鳥瞰図【第2回】(2017/03/16)































