数万から数10万台のCPUやHDDを使い、大規模なデータを分散管理・処理する。そのうちいくつかが故障しても処理を継続できる──。クラウドを支える、このような分散処理はどんな仕組みなのか。そこにはMapReduce、キーバリューストア、P2P通信といった技術要素がある。
分散システムは、複数台のコンピュータノード(以下、ノード)を用いることにより、システム全体としての処理能力を向上させたり、可用性を増大させることを目的にしたシステム形態である。処理するデータ量の増大に対してこれまでは、サーバーのCPUを増設する、リレーショナルデータベース(RDB)を増強する、といった対策で乗り切るケースが多かった。しかし、そうした対策はパフォーマンスとコストの両面から見て限界を迎えつつある。信頼性の高いサービスを低コストで提供するクラウドコンピューティングにとって、大規模な分散システムを実現することは極めて重要である。
ただし、分散システムには複数のコンピュータを単純に並べるだけは不十分で、それらを協調動作させる技術が不可欠だ。その上で大量のデータを高速に処理する性能と高い可用性を実現しなければならない。
本パートでは、インターネットイニシアティブ(IIJ)が独自に開発した「ddd(distributed database daemon)」を例に、低コストのPCを利用しながら信頼性の高い分散システムを実現する技術について解説する。
dddは、IIJのバックボーン回線を流れるトラフィックを解析することを目的に開発した分散システムである。現在では、セキュリティサービスやアプリケーションサービスのログ解析など、より広範なデータの処理に活用している。
ここで、分散システムを定義しておきたい。分散システムとは、多数のノードで構成されているが、それを利用するユーザーからは単一のものとして見えるシステムのことである。分散システムの例としては、巨大なデータを保持する分散ストレージや、分散データ処理などが挙げられる(図4-1、4-2)。近年、この分野では技術開発が活発に進められている。そのなかでも代表的な技術を、表4-1に挙げる。「Google File System」や「Amazon Dynamo」は分散ストレージ、「MapReduce」は分散データ処理技術に分類される(表4-1)。
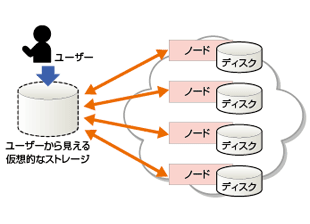
データを複数ノードで分散保持する。ユーザーからは1つのストレージに見える
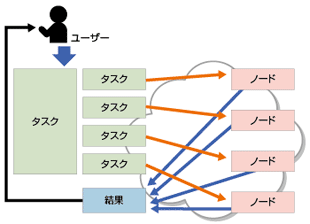
データ処理対象をたくさんのタスクに分割し、複数ノードで並列に処理する
| 分散ストレージ | Google File System(GFS) | 大量のデータを扱うためにGoogleで作られた分散ファイルシステム。実装は、Google外部には公開されていない |
|---|---|---|
| Amazon Dynamo | Amazonが開発した、分散キーバリューストア(key-value store)。実装は公開されていない | |
| 分散データ処理技術 | MapReduce | Googleで考案された大規模分散処理フレームワーク |
| Hadoop | 上記GFSとMapReduceを参考に作られた分散システム。Javaで記述され、オープンソースとして公開されている |
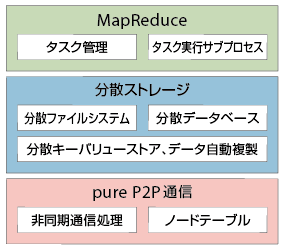
IIJが開発したdddは、その両方の機能を併せ持つ。dddの各ノードは、図4-3のような3層構造になっている。すべてのノードは同一の構造である。以下で、分散システムを実現するための各層の働きや特徴を見ていきたい。
データの抽出/加工をMapReduce技術で高速化
dddは、「フロー情報」と呼ぶ膨大なトラフィック情報を処理するため、MapReduce機能を搭載している(注:フロー情報については34ページの囲みを参照)。これにより、IIJでは数百億レコードを超える大量のトラフィック情報を対象に様々な条件で、かつ実用的な応答速度で解析できるようになった。
MapReduceは、Googleで考案された大規模データ処理のためのプログラミングモデルである。その名の通り、データを「map」と「reduce」の2段階に分けて処理するモデルで、多数のノードで効率よく分散並列処理を実行するために使われる(図4-4)。
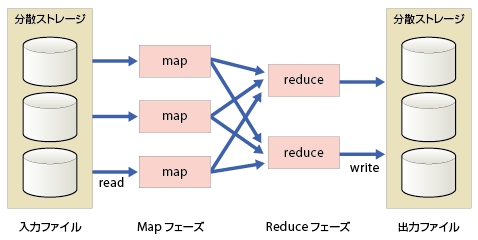
GoogleはMapReduceのソースコードは公開していないものの、仕組みに関する論文を発表している。今では、それを基に類似の機能を持った実装がいくつか出てきており、検索エンジンのインデックスの作成やログファイルの解析などに使われている。
mapとreduceは、分かりやすく言い換えると「抽出」と「集約」である。map(抽出)のフェーズではデータの中から必要な情報を抽出し、必要に応じて後の処理がしやすい形に変換する。reduce(集約)のフェーズでは、mapされた情報を集約する。処理内容それぞれに依存関係がないならば、その処理は複数のノードに分担させて並列実行できる。
MapReduceの最も単純で分かりやすい応用分野は、分散grepだろう。grepはUNIX系のOSに付属しているコマンドで、テキストファイル中から指定した文字列パターンにマッチする行を検索して出力するものである。grepは事前に検索のためのインデックスを作らず、その都度総当たりで調べるため、ファイルが巨大であったり大量にある場合は時間がかかる。このgrepコマンドにMapReduceを使えば、対象ファイルのgrep処理を複数ノードで分担できるため、全体の処理時間を短縮できる。
IIJは、このMapReduseの考え方に基づくデータ処理プログラムを独自開発した。このプログラムにおける処理の流れを説明しよう。
ユーザーはまず、解析対象や対象期間、データ抽出条件、グルーピングの軸といったパラメータを含む「MapReduceジョブリクエスト」を準備する。次に、dddのノードのどれかに対してそのリクエストを送信する。リクエストを受けたノードは、対象期間を一定間隔で分割する形で、MapReduceジョブを複数のmapタスクとreduceタスクに分解する。mapタスクは各ノードに割り振られ、各ノードはパラメータに従って抽出やグルーピングといった処理を実行する。
各ノードでのmapタスクの実行が終わったら、reduceタスクを起動して結果を集約する。集約された結果は、分散ストレージに書き出される。または、ユーザーのマシンに直接返すこともできる。
会員登録(無料)が必要です


- 1
- 2
- 次へ >


-

-

-

-

Gemini搭載でGoogle CloudのAIプラットフォーム「Vertex AI」が大幅アップデート。企業の生成AI活用に不可欠なデータマネジメントとは
-

-

-

-

-

-

-

-

-

-

-

-

-

-

大型化、狭額縁化だけじゃないモニターの進化! “機能”と“信頼性”を両輪に差別化を推し進めるレノボの「ThinkVision」
-

WalkMeが2023年のデジタルアダプションアワードを発表。「えきねっと」におけるUX向上事例など、ユーザー間でノウハウを共有するイベントを開催
-

-

Lenovo Tech World Japan 2023 特別対談「レノボ×マイクロソフト」が語る生成AI活用の“現在地”と“近未来”
-

-

-

あらゆるユーザーにAI活用を!「Lenovo Tech World Japan」で提示される企業コンピューティングの近未来像とは?
-

-

-

-

-

-

-
