富士通研究所は2010年9月6日、メール添付文書を介した機密情報の漏洩を文字列認識によって防止する技術を発表した。文書の印刷データを文字列認識の対象とすることによって、印刷後イメージを対象とした既存の方式よりも文字列の検出精度が高まる。2011年度の実用化を目指す。
最大の特徴は、文書ファイルを、Windowsの汎用印刷データ形式であるEMF(Enhanced Metafile)に変換する点。これにより、印刷データを、テキスト(文字コード)、線画図形(ベクトル・フォントなど)、ビットマップ画像、の3つに分類できる。これら3つの要素を個別に扱うことで、異なる要素が重なって印刷される場合や、異なる要素間の距離が近い場合に、文字列認識の精度が高まる。
具体的な利用ケースの例は、文書に含まれる、背景文字(透かし文字)や社外秘マーク画像、など。特に、背景文字はテキスト情報と重なっているため、印刷後イメージ全体を対象とした既存の文字列認識方式では検出が難しい。社外秘マーク画像も、画像部分が他の要素と距離が近い場合、解析のためのノイズが多くなり、既存方式では検出速度や精度が下がる。
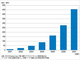
同社が新方式と既存方式の文字列検出率を比べた実験結果は、以下の通り。Word/PDFを対象とした背景文字(透かし文字)の検出率は、新方式の99%に対して、既存方式では検出できなかった。テキストを模したマーク画像の検出率は、PDFが新方式で95%、既存方式が93%。Excel/Word/PowerPointが新方式で99%、既存方式で89%。
なお、同社では、同技術の詳細を、2010年9月14日から行われる「電子情報通信学会ソサイエティ大会」で発表する。