2020年を見据えた「グローバル企業のIT戦略」を取り上げる本連載。IT戦略における日本と世界の差異を見極めるための観点として、前回からビッグデータ(Big Data)の目的や特長、手法、活用シナリオと可能性、課題点、そして、あるべき姿について考えている。前回は、ビッグデータ活用に潜む“想定外”の課題を指摘した。今回は、ビッグデータ編のまとめとして、ビッグデータ活用のあるべき姿を提案する。
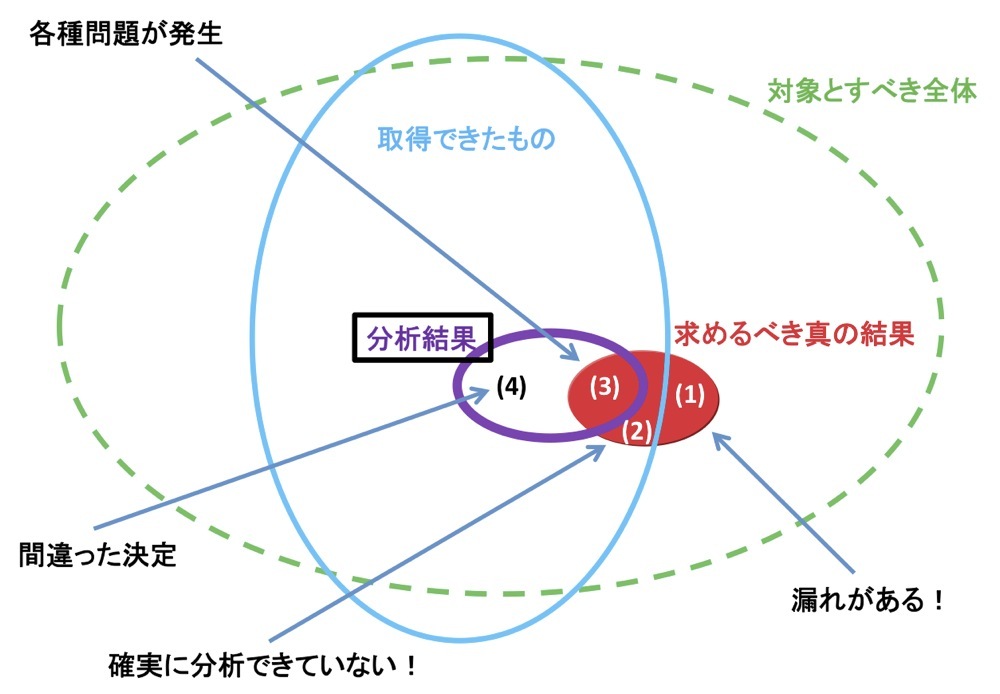 図1:無限データ/Any Dataのビッグデータ分析
図1:無限データ/Any Dataのビッグデータ分析拡大画像表示
第15回で述べたように、科学的な分析手法からみたデータの分類方法には、有限データと無限データ(エニーデータ、Any Data)がある。無限データを対象にしたビッグデータの分析結果は、図1のような形になることは、第13回で紹介している。分析の過程で対象範囲が、全体(破線)、取得できたデータ(実線)、分析結果(太線)と、徐々に小さくなることは、容易に理解できる。
有限データのビッグデータ分析では“想定外”が当然に
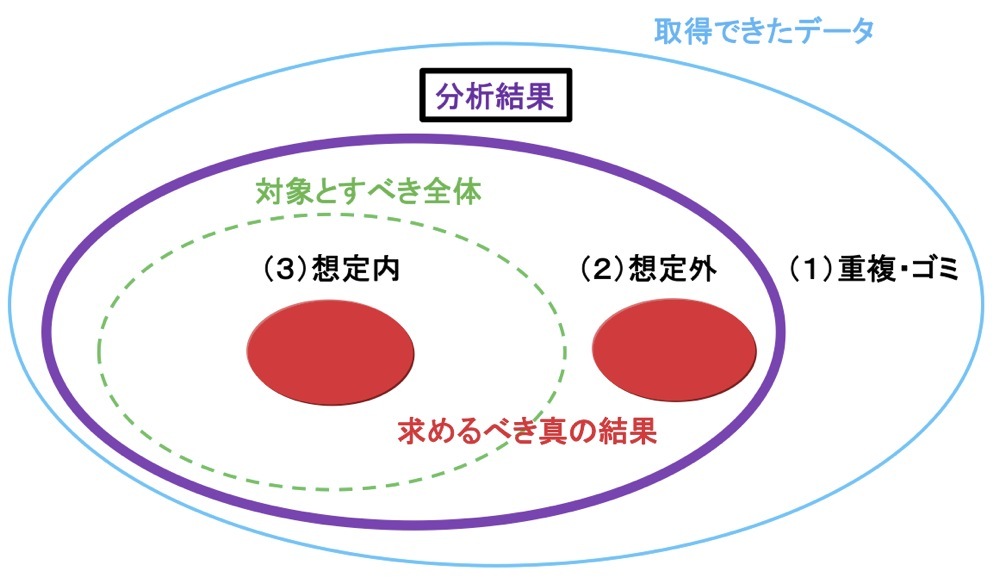 図2:有限データのビッグデータ分析
図2:有限データのビッグデータ分析拡大画像表示
ところが、有限データの場合は様相が違う。対象にすべき全体(破線)よりも、実際に取得できるもの(実線)や分析結果(太線)のほうが大きくなる(図2)。結果、求めるべき真実は“想定外”のところにあったりする。どういうことか、分かりやすく説明してみよう。
例えば、A市が持つ各種データを分析するとしよう。対象は、A市に住んでいる住民全体である。ところが、市が管理している複数のデータソースを統合してみると、実際に住んでいる住民数の3~4倍規模の住民データが集まってくる。統合したデータの中には、データの重複があったり“ゴミ”が混ざったりしているためだ。
重複は、各々のデータソースで間違って入力されていたり、表記方法が違っているために同じ人を別の人と判断したりすることで起こる。一方の“ゴミ”は、既に転出している住民のデータなどが一部のデータソースに残っていることで発生する。逆に、実際には転入しているのに住民票を移していないなどの漏れもあるだろう。
会員登録(無料)が必要です


本連載『2020年を見据えたグローバル企業のIT戦略』の第1回〜第12回が「クラウド、GRC編」として、IT Leadersの電子書籍『IT Leaders選書』になりました。お手元でじっくりとお読みいただけます。こちらから、どうぞ、お買い求めください。
- 1
- 2
- 3
- 4
- 次へ >
- 【第24回】IoT が実現する社会に向けた戦略を確立せよ(2015/10/05)
- IoTで活性化するロボットとAI─感情をデジタルで扱うために:第23回(2015/09/07)
- 【第22回】IoTでデータを再集中させるセンサーの課題が未解決(2015/08/03)
- 【第21回】IoTが導く第3のドリブンは“エモーション(感情)”(2015/07/06)
- 【第20回】IoT活用で問われているのは発想力、ブレインライティングが有効(2015/06/01)






























