Preferred Networks(PFN)は2017年11月10日、ディープラーニング(深層学習)用途のために同社が2017年9月に稼働させたスーパーコンピュータシステム「MN-1」を使い、ディープラーニングの学習速度で世界最速を実現したと発表した。これまで31分かかっていた学習を15分で完了させたという。
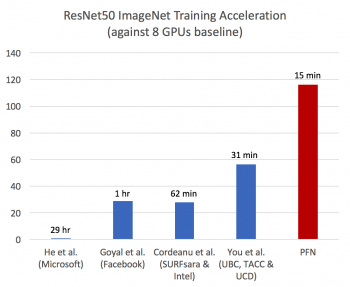 図1●ImageNetの画像分類データセットを利用したResNet-50の学習時間のグラフ(出所:Preferred Networks)
図1●ImageNetの画像分類データセットを利用したResNet-50の学習時間のグラフ(出所:Preferred Networks)拡大画像表示
Preferred Networks(PFN)は、1024個のGPUで構成する大規模並列コンピュータ「MN-1」と、分散深層学習フレームワーク「ChainerMN」用いて、ディープラーニングの学習を行った。この結果、ImageNetの画像分類データセットを利用したResNet-50の学習を15分で完了した。これまでに報告されていた最速時間の31分と比べて大幅に短縮した。
今回の研究成果は「Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes」というタイトルで公開している(https://www.preferred-networks.jp/docs/imagenet_in_15min.pdf)
今回の学習にあたっては、複数のコンピュータを使った並列分散学習の効率を高めるため、学習アルゴリズムと並列化の改善を行っている。「GPU数に応じて処理性能がリニアに向上していくわけではない。GPU数が増えるほどバッチサイズが大きくなるほか、GPU間通信のオーバーヘッドによって、得られるモデルの精度や学習スピードが徐々に下がる」(同社)。
なお、今回学習に用いたMN-1は、ディープラーニングの研究開発を目的にPFNが構築したスーパーコンピュータシステムである。分散深層学習フレームワークのChainerMNを複数のGPU搭載サーバーに分散処理させることにより、ディープラーニングを高速に利用できるようになる。
GPUの基盤として、NTTコミュニケーションズとNTTPCコミュニケーションズが提供しているサービスを利用している。GPUは、米NVIDIAの「Tesla P100」を1024個使っている。理論上のピーク性能は合計で4.7PFLOPS(毎秒4700兆回の浮動小数点演算)になり、民間企業のプライベートな計算環境としては国内最大級となる。































