筆者らのデータ分析チームは、「KDD Cup 2015」というデータ分析の国際大会で2位に入賞しました。前回は、データ分析競技の課題を正確に理解し、データの実像に迫るために有効な分析プロセスを紹介しました。今回は、コンピュータがデータの持つ意味を理解できるように、人間が与えなければならない情報について紹介します。現時点のコンピュータは残念ながら人間のようにデータから特徴を抽出できないからです。
人間はデータを眺めれば特徴をつかめます。例えば、前回説明したように、「KDD Cup 2015」のデータを観察することで筆者らは、「MOOC(Massive Open Online Courses、大規模オープンオンライン講義)を脱落する人は訪問日数が少ない」という特徴を見出せました。
しかし、今のところコンピュータは、私たち人間のようには、データから特徴を抽出できません。そのため、人間が特徴に関する情報を与える必要があります。最近では人工知能の分野で登場した“Deep Learning”という技術により、データから特徴を抽出するプロセスの自動化が期待されています。ですが、人間のような認知能力の獲得には至っていません。
特徴量の抽出こそが予測精度の向上につながる
KDD Cup 2015のデータを具体例として、実際にコンピュータに与える情報とは何かを見ていきましょう。KDD Cup 2015の課題は、「MOOCにおける受講者の脱落を予測する」でした(第1回参照)。
本競技のデータには、履修登録(enrollment_id)単位に脱落したかどうかのフラグが付与されています。そこで図1に示すように、アクセスログ(縦に長いデータ)をenrollment_id単位で重複のない状態(ユニーク)にします。そのうえで、脱落を特徴付ける量、つまり第2回で紹介したサイトへの「訪問日数」などが横に並ぶように変換する必要があります。
 図1:特徴量の抽出に向けたデータ変換のイメージ
図1:特徴量の抽出に向けたデータ変換のイメージ拡大画像表示
データ分析の世界では「訪問日数」のような量を「特徴量」と呼びます。この特徴量と予測対象(脱落の有無)の関係を簡単な数式で表現すると、みなさんも昔、学校で習った次のような式になります。
Y = f(X)
このような数式(モデル)を定義することで、「訪問日数がx日の人の脱落確率はy%」といった予測が可能になるのです。データから有効な特徴量を抽出することは、モデル構築の重要なプロセスの1つです。専門的には「Feature Engineering」と呼ばれています。
競技における予測モデルの構築プロセス全体を示したのが図2です。特徴量を抽出した後にモデルに投入し、精度を測定することで有効性を検証します。このとき、予測モデルの構築プロセスは大きく2つに分かれます。(1)特徴量の抽出と、(2)適切なアルゴリズムによるモデル構築の両プロセスです。
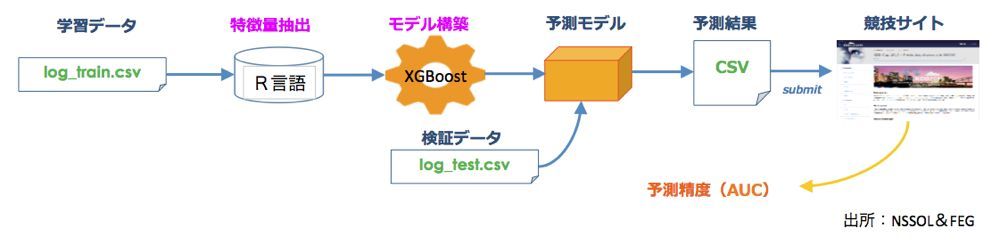 図2:予測モデルの構築プロセス
図2:予測モデルの構築プロセス拡大画像表示
本競技の主催者の一人であるRon Bekkerman氏はブログで「アルゴリズムによるモデルの構築と比較すれば、特徴量の抽出プロセスのほうが勝敗を分ける要因として重要だった」と指摘しています。
なぜなら、モデル構築用のアルゴリズムである「XGBoost」が登場したからです。XGBoostは、GitHubで公開されているフリーのパッケージで、統計解析用言語であるRや汎用言語のPythonから利用できます。驚異的な予測性能を誇り、本競技で入賞した10チームのすべてが利用していました。
他のデータ分析競技でも、XGBoostは標準的に利用されています。つまり、モデル構築プロセスでは工夫を凝らす余地が少なくなってきているのです。結果、特徴量の抽出が競争優位の源泉になります。特徴量の抽出には決まった方法がなく、分析者のアイディア次第で独創的な特徴量を抽出できます。本競技で3位に入賞した「Data Robot」のチームメンバーであり、Kaggleランク世界第1位(競技開催時)のOwen Zhang氏も、あるインタビューの中で、特徴量の抽出は「アドホック(反復性がない、その場限り)」だと語っています。
一方、モデルの予測精度を示す指標に「AUC」があります。0から1の範囲の値をとり、1に近いほど予測精度が高いことを示します。前述のBekkerman氏のブログによれば、AUCが0.895以上の31チームが入賞を争っていました(図3)。筆者らが特徴量を入力したXGBoostは、最終的には0.908以上のAUCを達成しました。極めて有効な特徴量を抽出できたことを示す証左と言えるでしょう。
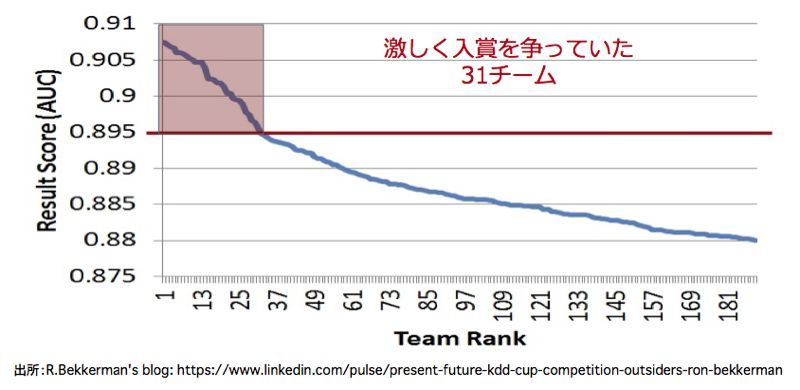 図3:参戦チームとモデル精度(AUC)
図3:参戦チームとモデル精度(AUC)拡大画像表示
その前提として、チーム全体では2600項目以上の特徴量を抽出しています。これを可能にしたのは、クラウド分析基盤上に実現した特徴量の量産スキームです。筆者らは、競技期間の序盤から中盤にかけては個人として参戦し、それぞれが競い合い独自に特徴量を抽出していました。その特徴量をクラウド基盤上で共有することで”車輪の再発明”、すなわち同じ特徴量を複数人が抽出しようとすることを防いだのです。こうした組織における競争と協調のマネジメントについては第5回で詳しく説明します。
本稿を執筆するに当たり、チームメンバーが採用していた特徴量の抽出方法を整理したところ、大きく2つの方法を利用していたことが分かりました。「データ構造を起点として特徴量を量産する方法」と「ユーザー行動を起点として有効な特徴量を探索する方法」です。後者では、第2回で紹介しきれなかった“”重大な発見”についても詳しく述べます。
抽出法1:データ構造を起点として特徴量を量産する
この方法では、データの構造から対象範囲・集約方法・指標を考え、新たな特徴量を抽出します。簡単に特徴量を量産できるので、特徴量の抽出に取り掛かる初期段階で実行します。
本競技の課題においても、最初はデータ構造から特徴量を抽出しました。例えば、アクセスログのデータ構造を中心に考えてみると、下記のような候補が挙げられます(実際にはこの他にも多くの候補があります)。
(1)対象範囲
・全体
・特定の曜日/時間帯やX週間(timeの変換)
・特定のイベントのみ(objectに緋づいたevent)
(2)集約方法
・履修登録単位(enrollment_id)
・ユーザー単位(username)
・コース単位(course_id)
(3)指標
・ログ数(logテーブルのレコード数)
・アクセス日数(timeを日付に変更して重複排除カウント)
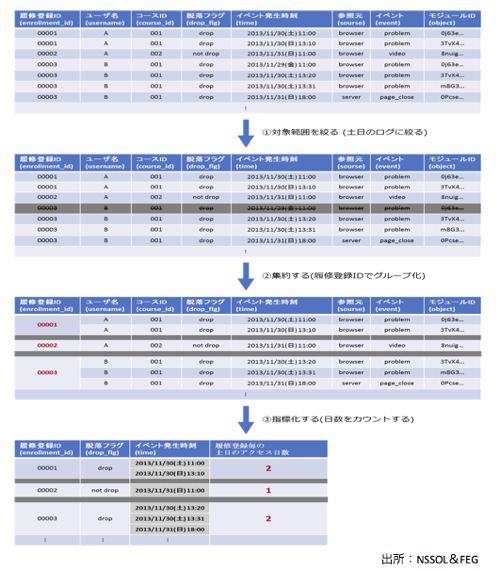 図4:データ構造から作る特徴量の例。履修登録ごとの土日のアクセス日数の場合
図4:データ構造から作る特徴量の例。履修登録ごとの土日のアクセス日数の場合拡大画像表示
これらを組み合わせることで、様々な特徴量を抽出できます。例えば、「履修登録毎の土日のアクセス日数」や「ユーザー毎のproblemへのログ数」などです(図4)。
特徴量を組み合わせて抽出する際には、人間の手間をかけずに、プログラムで自動列挙します。当然、特徴量の数は、パターン数が増えると指数的に増えてしまい、処理時間が長くなり特徴量選択も難しくなってしまいます。ですが、XGBoostのようなアルゴリズムの登場によって、並列処理による高速化や特徴量の自動選択が可能となったことで、従来と比較して膨大な数の特徴量を扱えるようになったのです。
応用例として、データの階層構造を考慮して特徴量を抽出するアプローチがあります(図5)。
 図5:階層構造から作る特徴量の例
図5:階層構造から作る特徴量の例拡大画像表示
本競技の課題においては、オンライン学習コースのobject(動画や問題等のカリキュラム)のアクセスデータがあります。問題や説明のページはコースごとに違うので、全コースをまとめて1つのモデルで特徴量のすべてを適切に学習することは困難です。そこで、コースごとに問題や説明ページへのアクセス回数を特徴量として利用したモデルを構築し、コースごとのモデルが出力した離脱しそうな確率の値を新たな1つの特徴量として利用します。これによって、数千項目以上の特徴量を加味したモデルを構築できました。
実際には、さらに過学習が発生しにくいような工夫を加えていますが、ここでは割愛します。上記の応用例は、他の上位チームでは実践されておらず、独自性の高いアプローチであったと言えます。
データ構造から特徴量を抽出する方法は、慣れれば簡単に特徴量を量産でき、高い精度のモデルを素早く作れます。実際にチームメンバーの1人は、本競技にかなり遅れて参戦したのですが、上記の2つの方法から特徴量を量産した結果、2週間で個人戦にて暫定10位以内に入っていました。この方法は、データベースの設計などに携わっている人にとっては学びやすく、最初に身に着ける特徴量の抽出方法として最適です。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- データ分析の新潮流と、未来を支える人材像:最終回(2016/05/12)
- データを“武器”にするためのビジネス思考とは【第6回】(2016/04/21)
- データサイエンティストのチーム力学【第5回】(2016/03/17)
- 実像に迫るためにコンピューターを鍛え上げる【第4回】(2016/02/16)
- データから、そのデータを生み出した実像をつかむ【第2回】(2015/12/17)
データサイエンティスト / アナリティクス / BI / 日鉄ソリューションズ






















