電子情報通信学会(IEICE)が、学術論文や企業の技術報告書などを対象とした文献検索システム「I-Scover」のバージョン2を2017年3月にサービス開始した。提供開始から約半年経ったが、学術関係者だけでなく企業でも利用する価値は大きそうだ。例えば、伸びが期待される研究分野や有望な研究者の調査・把握が効率的になる。一方、I-ScoverはLinked Data(リンクトデータ)技術を用いたデータベースシステムの構築事例としても興味深い。リンクトデータは組織横断的なデータの利活用を促すきっかけになる。同学会がこの仕組みを開発した背景には、学会に求められる役割の変化があった。I-Scover開発に携わった2人のキーパーソンに聞いた。
【キーパーソン紹介】
井上 友二 氏

1973年に九州大学大学院(修士)修了後、電電公社(現・NTT)に入社。ディジタルネットワークの研究開発と国際標準化などに従事。1998年にNTTマルチメディアネットワーク研究所長、2000年にNTTデータ取締役、2002年にNTT取締役としてNTTグループ全体の研究開発責任者。2007年から一般社団法人情報通信技術委員会理事長。2010年から株式会社トヨタIT開発センター代表取締役会長(現在は顧問)。2013年電子情報通信学会(IEICE)会長(現在は退任)。IEEE及び、IEICEのフェロー
武田 英明 氏

国立情報学研究所 情報学プリンシプル研究系 教授。総合研究大学院大学 教授。1991年、東京大学工学系研究科博士課程修了。工学博士。1992~1993年、ノルウェー工科大学、1993~2000年、奈良先端科学技術大学院大学を経て現職。特定非営利活動法人 リンクト・オープン・データ・イニシアティブ理事長
I-Scoverの開発目的と特徴
──まずは、元会長である井上さんに、電子情報通信学会(http://www.ieice.org/jpn/)の現況とI-Scoverの開発経緯を伺います。今年5月にちょうど創立100周年を迎えたそうですが。
井上:電子情報信学会(IEICE)では、会員数約3万4000人を擁し、これまで多くの学会を開催してきました。一般的に、学会は最新の研究発表として、また研究の動向や人材とのネットワーキングの場としても重要な役割を果たしています。IEICEを通じて発表された論文の総数は約22万件に達します。これらの情報は、研究活動の促進に欠かせないものと自負しています。
ただ、こうした貴重な知見が世の中にきちんと還元されているか、というと疑問符が付きました。理由は、論文や研究活動が分野別にそれぞれ別のシステムやWebサイトで縦割りで管理されているため、網羅的に検索できず、求める情報にたどり着くまで時間やコストを要する、または辿りつかないケースが多かったからです。
そうした要望をもとに開発してきたのが、「I-Scover」(アイスカバー、正式名称はIEICE Knowledge Discovery)です。開発プロジェクトが本格始動したのは、2011年のことです。
 図1a I-Scoverのトップ画面
図1a I-Scoverのトップ画面拡大画像表示
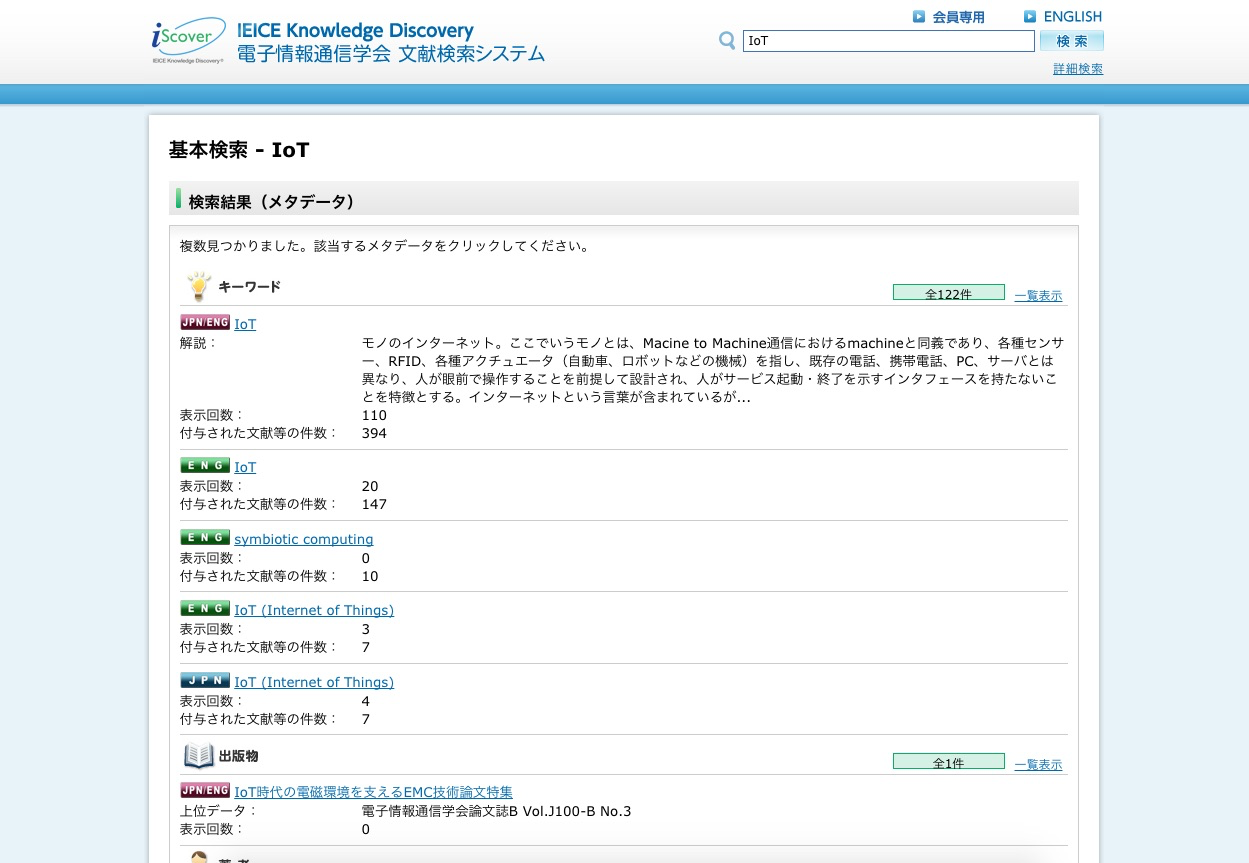 図1b I-Scoverにおいて「IoT」で検索した結果
図1b I-Scoverにおいて「IoT」で検索した結果拡大画像表示
──検索システムとしてのI-Scoverの特徴にどこにあるでしょうか。
井上:一般的な全文検索システムに比べて、複雑な検索が可能であることです。文献の検索に加え、人物や技術キーワードに関する情報の検索にも活用できます。さらに、この検索ポータル経由での検索だけでなく、APIを介した高度な分析もできます。実際に、I-Scoverを利用したアイデアを募るコンテスト「I-Scoverチャレンジ」では、ユニークな活用例が発表されています。
 井上友二氏
井上友二氏例えば、「トレンドレポーター」というWebアプリがあります。これは任意のキーワードを入力すると、I-Scoverの中から引っ張ってきたデータからトレンドレポートを動的に生成するというシステムです。同一文献に頻繁に現れるキーワードの関係(共起語グラフ)を俯瞰できるため、研究のトレンドを直感的に把握することができます。
 図2 「トレンドレポーター」において「IoT」で検索した結果 http://iscover.ce.fit.ac.jp/trend/?q=IoT
図2 「トレンドレポーター」において「IoT」で検索した結果 http://iscover.ce.fit.ac.jp/trend/?q=IoT拡大画像表示
──企業の研究開発部門などはこれまで、著名な研究者であればともかく、これから有望な研究領域を支える若手研究者などが、誰でどこに所属しているのか、などの情報をなかなかつかめませんでした。I-Scoverを利用するメリットは企業にもありそうですね。
井上:ええ。研究の体制も単独ではなく、複数のメンバーで行い、論文を発表するケースが多くあります。I-Scoverの検索結果から研究者間のつながりやコミュニティも見えてくるので、どのようなコミュニティが活発なのか、あたりがつけやすくなります。
I-Scoverを支える仕組み ~メタデータとリンクトデータ~
──ところで、高度な分析が行える仕組みを実現する上で、ポイントになったのは何でしょうか。
井上:Linked Data(リンクトデータ)という技術にあります。この分野に詳しい、国立情報学研究所の武田先生などに協力してもらいました。
 武田英明氏
武田英明氏武田:私は情報学分野の研究者であると同時に、学術情報の流通促進に関する様々な活動を推進しています。リンクトデータによって、単純な全文検索システムでは得られない機能を持たせることができました。リンクトデータの技術を、一定のルールの下で再配布や二次利用ができるオープンデータに適用したのが、リンクトオープンデータ(Linked Open Data:LOD)と呼ばれます。もともとLODは欧州が発祥で、オープンサイエンスの発想に基づいています。学術分野では事実上の世界標準と言えます。
井上:昨今は企業においても、課題解決に分野横断的な知見を求められる学際領域が増えています。今回、そうした背景を踏まえて、武田先生をはじめとし、私たち電子情報通信学会で開発プロジェクトのメンバーがリンクトデータについて学びました。
リンクトデータは、ネットワーク(グラフ)型のデータ構造を保持します。その文法は、基本的には、トリプルと呼ばれる「主語・述語・補語」あるいは「主語・述語・目的語」の並びでデータをつなげていく、というシンプルなルールを持っています。このトリプルで構築されたネットワーク型のデータベースを、SPARQLというオープンな仕様のクエリ言語を用いて参照したり更新したりします。
武田: 表形式のRDB(リレーショナルデータベース)と異なる点は、データ同士をつなぐネットワークには、後から別のデータを追加していくことが容易である点です。
例えば、owl:sameAsという記述用語を使って、AとBが同じであると対応づけると、名寄せができます(参考情報: http://schema.org/sameAs )。Aか、Bか一方に片寄せするのではなく両方の表記を持つデータを並存しつつ、既存のシステム間のデータを生かした形で流通させることが可能になります。リンクトデータの持つ柔軟性は、システム間の相互運用性(Interoperability)を高めることになります。
井上:2017年3月にはリリースした際にはSPARQL APIが提供されています。併せて、SPARQLクエリーをチェックしたりできるインタフェース(SPARQLエンドポイント)も用意しているので気軽に触れていただきたいと考えています。
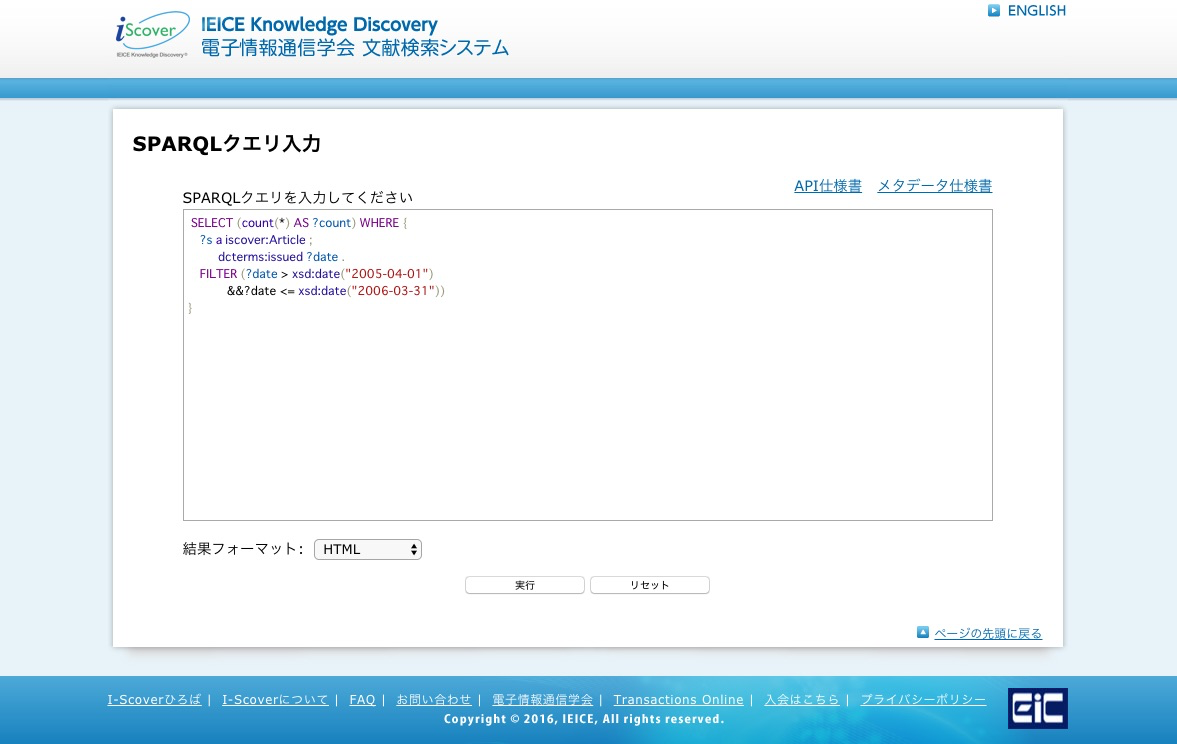 図3 I-Scoverに用意された、SPARQLクエリを入力できるエンドポイント 関連リンク:SPARQLクエリの例 http://www.ieice.org/~iscover/iscover/?page_id=1210
図3 I-Scoverに用意された、SPARQLクエリを入力できるエンドポイント 関連リンク:SPARQLクエリの例 http://www.ieice.org/~iscover/iscover/?page_id=1210拡大画像表示






















