[ユーザー事例]
日本発の生成AI/LLMでイノベーションを!─先進企業が「AWS LLM開発支援プログラム」の成果を発表
2024年3月6日(水)五味 明子(ITジャーナリスト/IT Leaders編集委員)
生成AI/大規模言語モデル(LLM)の世界的なトレンドの中、日本企業はこの先、どれほどの成果を生み出していけるのだろうか──。アマゾン ウェブ サービス ジャパン(AWSジャパン)主導の「AWS LLM開発支援プログラム」は、国内の先進企業の取り組みの進捗を知る好機となった。2024年1月31日に開かれた成果発表会では、NTT、ストックマーク、リコーなどが自社のLLM開発に関するプレゼンテーションを行った。本稿では、各社の発表内容を紹介しながら、日本の生成AI/LLM開発の現在位置を概観してみたい。
AWS LLM開発支援プログラムとは
「AWS LLM開発支援プログラム」は、大規模言語モデル(LLM)の開発を行う日本企業/団体を支援するAWSジャパンのイニシアチブだ。LLM開発を行うための計算機リソース選定/確保のガイダンスやLLM事前学習のためのAWSクレジットの提供などが含まれている。
この取り組みが公になったのは2023年7月3日。AWSジャパンは、日本国内に法人や拠点を持つ10程度の企業/団体を対象に、LLM開発に必要な以下の4つの支援を提供すると発表している(図1)。
●計算機リソース選定と確保のガイダンス:利用するモデルやディープラーニング(深層学習)フレームワークなど、個々の参加者の技術要件に応じた適切なインスタンスの選定や、その計算機リソースをAWS上で確保するためのガイダンスを提供
●技術相談・ハンズオン支援:AWS上での分散学習、クラスタリング時のネットワーク性能の最適化、マネージドサービスの活用、AWS TrainiumやAWS Inferentiaの利用方法などをAWSの技術エキスパートがサポート
●LLM事前学習用の「AWSクレジット」:総額で600万ドル規模のクレジットをAWSが提供し、事前学習用のワークロードに必要な計算機リソースの費用などを一部支援
●ビジネスプラン/ユースケースに関する支援:開発したLLMをビジネスに活用する方法やAWS Marketplaceなどを活用したLLMの公開・販路拡大、ベンチャーキャピタルとのコミュニケーションなどを支援
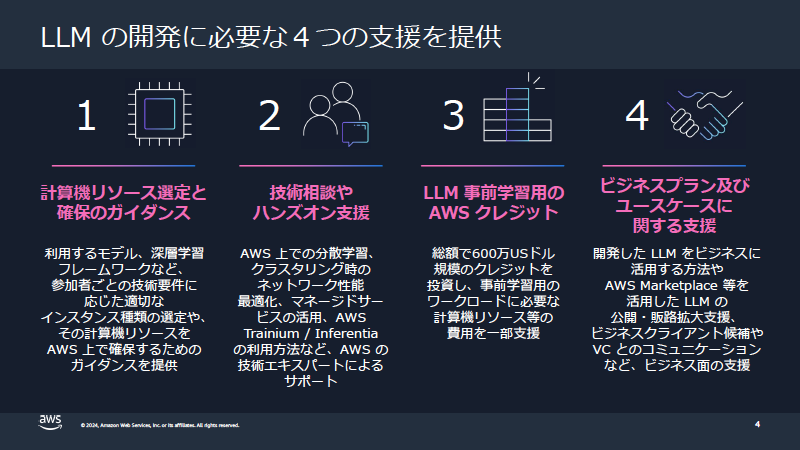 図1:AWS LLM開発支援プログラムで参加企業に提供された4つの支援(出典:AWSジャパン)
図1:AWS LLM開発支援プログラムで参加企業に提供された4つの支援(出典:AWSジャパン)拡大画像表示
発表と同時にプログラム参加企業の募集が始まり、1カ月後の2023年8月に選考会、その後、採択企業はプランニング期間を経てAWSジャパンの支援を受けながらLLM開発を進め、その最終成果発表会が2024年1月31日に開催された。
プログラム採択企業として公開されているのは17社(表1)。うち発表会に登壇したのは15社。NTT、リコー、リクルートといった大企業から、Turingや松尾研究所など注目のスタートアップまで、規模も業種もさまざまな企業が参加している。
| カラクリ | マネーフォワード |
| サイバーエージェント | ユビタス |
| ストックマーク | Lightblue |
| Spariticle | リクルート |
| Turing | リコー |
| NTT | rinna |
| Preferred Networks | ロゼッタ |
| Poetics | わたしは |
| 松尾研究所 |
表1:採択企業17社(公開可能な企業・団体)。スタートアップから大企業まで、業種業界を問わず多くの国内企業が独自のLLM開発に取り組む(出典:AWSジャパン)
特徴はAWSジャパンが企画し、日本企業が独自にLLM開発に取り組むことにフォーカスした支援プログラムであるという点だ。2022年11月に米OpenAIのChatGPTが登場して以来、数多くの生成AIサービスが登場して生成AIの一大ブームを形成している。そうした中、LLM開発に挑む日本企業も少なくないが、LLMの開発にはAIの専門知識や大量の計算機リソースが必要となり、開発のハードルは決して低くない。
同プログラムはこうしたハードルに悩む日本企業、それもすでにある程度のLLM開発のスキル/経験(選考時点で数十億~1000億パラメータ規模のLLMを事前学習・構築済み)を持つ企業に対し、半年間という期間限定でAWSジャパンが支援を行うことで、スピーディで現実的なLLM開発の成果を出すことを目的としている。
プログラム発足時に経済産業省はこんなエンドースメントを寄せている。「日本は企業も行政も生成AIの活用に前向きだが、活用するだけでなく、開発力を日本の国力として保持していきたい」(商務情報政策局情報産業課 ソフトウェア・情報サービス戦略室長の渡辺琢也氏)。日本のLLM開発を促進するという意味でも、支援を受けた日本企業が期間内に具体的な成果を示すことは重要なマイルストーンとなる。
発表会の冒頭、AWSジャパン 執行役員 事業開発統括本部長の佐藤有紀子氏(写真1)は、「同プログラムで目指したのは日本企業の生成AI開発を支援し、日本のイノベーションを加速していくこと。生成AI/LLMの進化にもスピーディに対応できるAWSならではの強みを生かせたサポートであり、日本企業のイノベーションのDay 1を具現化できたと思っている」と述べ、約半年間で多くの成果を得られたことを強調している。
 写真1:AWSジャパン 執行役員 事業開発統括本部長の佐藤有紀子氏。AWSは2023年7月のプログラム発足時からエグゼクティブスポンサーとして関わってきた
写真1:AWSジャパン 執行役員 事業開発統括本部長の佐藤有紀子氏。AWSは2023年7月のプログラム発足時からエグゼクティブスポンサーとして関わってきたAWSジャパンから半年間という期限付きで支援を受けた採択企業は、実際、LLMの開発においてどのような成果を示すことができたのだろうか。以下では発表された中からNTT、ストックマーク、リコーの開発事例の要旨を紹介する。
小さな知の集合体「tsuzumi」─NTT
NTTは2023年11月1日、日本語処理において特に高い性能を発揮する独自開発の軽量LLM「tsuzumi(つづみ)」を発表、2024年3月に商用サービスとして提供開始を予定している(図2)。
開発チームはtsuzumiの開発環境の1つとして、AWS LLM開発支援プログラムに参加。世界中で急激な需要増となっている「NVIDIA H100 GPU」96基を調達して取り組んでいる(関連記事:NTT、1GPUで推論動作可能な軽量LLM「tsuzumi」を発表、2024年3月に商用化)。
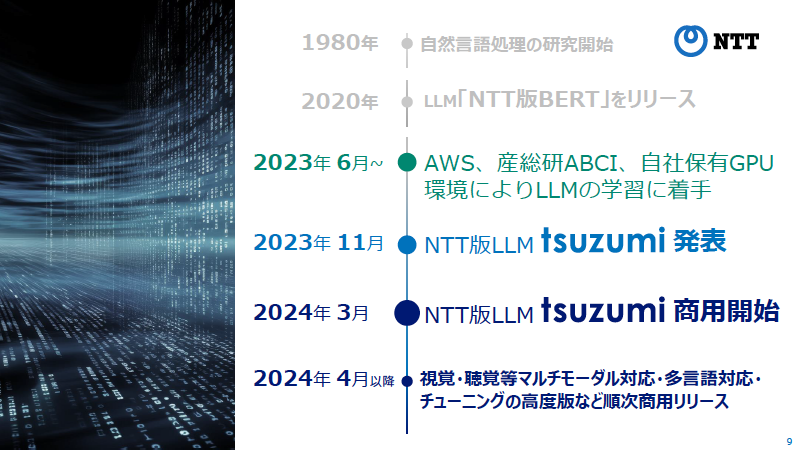 図2:NTTが開発した軽量LLM「tsuzumi」の開発/リリースまでの流れ。1980年代から行ってきた自然言語処理の研究が礎となっている(出典:NTT)
図2:NTTが開発した軽量LLM「tsuzumi」の開発/リリースまでの流れ。1980年代から行ってきた自然言語処理の研究が礎となっている(出典:NTT)拡大画像表示
プログラムに参加して、GPUクラスタの構築/運用のテクニカルサポートをAWSジャパンから受けたほか、LLM学習ライブラリの環境移行、インスタンス間の高速ノード通信を実現するEFA(Elastic Fabric Adapter)の活用など、多くの恩恵を得ているという。特に、確保が非常に難しくなっているH100 GPUを大量に調達してスムーズに環境を立ち上げ、マルチノードによる学習を迅速に進められたことは、tsuzumiの開発プロジェクトで大きなポイントになったと言える。
また、LLM学習環境については、NTTのオールフォトニクスネットワーク(APN:全光ネットワーク)「IOWN APN」を利用し、学習データを手元に置きながら100km離れたデータセンター(神奈川県横須賀市)のGPUを利用するソブリンハイブリッド環境を構築、ローカル環境と遜色ない低遅延のLLM学習環境を実現している(図3、関連記事:NTT、エッジ拠点のカメラ映像を100km離れたデータセンターで高速にAI分析する実証実験)。
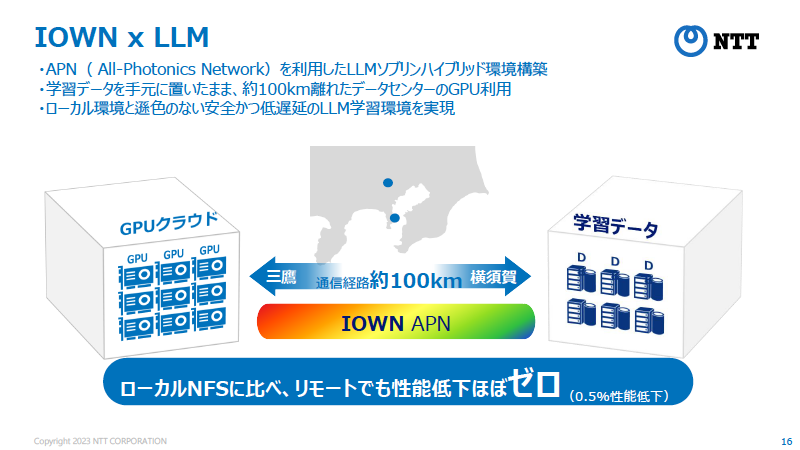 図3:tsuzumi開発ではオールフォトニクスネットワーク(APN:全光ネットワーク)の「IOWN APN」を活用、GPUデータセンターと学習データが約100km離れたリモート環境でもローカルと遜色ないパフォーマンスでLLM開発を実現(出典:NTT)
図3:tsuzumi開発ではオールフォトニクスネットワーク(APN:全光ネットワーク)の「IOWN APN」を活用、GPUデータセンターと学習データが約100km離れたリモート環境でもローカルと遜色ないパフォーマンスでLLM開発を実現(出典:NTT)拡大画像表示
発表を行ったNTT人間情報研究所 上席特別研究員の西田京介氏(写真2)は、tsuzumiというLLMの特徴を「大量の計算機資源を必要とする大きなAIではなく、専門性や個性を持った小さなAIの集合知」と表現する。tsuzumiのパラメータサイズは超軽量版で6億、軽量版で70億となっており、OpenAIが提供するGPT-3の1750億に比べると大幅に少ない。「和楽器の鼓のように小さくてチューニングしやすく、さらにマルチモーダルで日本語に強いLLMを目指した」(西田氏)という(図4)。
 写真2:NTT人間情報研究所 上席特別研究員の西田京介氏
写真2:NTT人間情報研究所 上席特別研究員の西田京介氏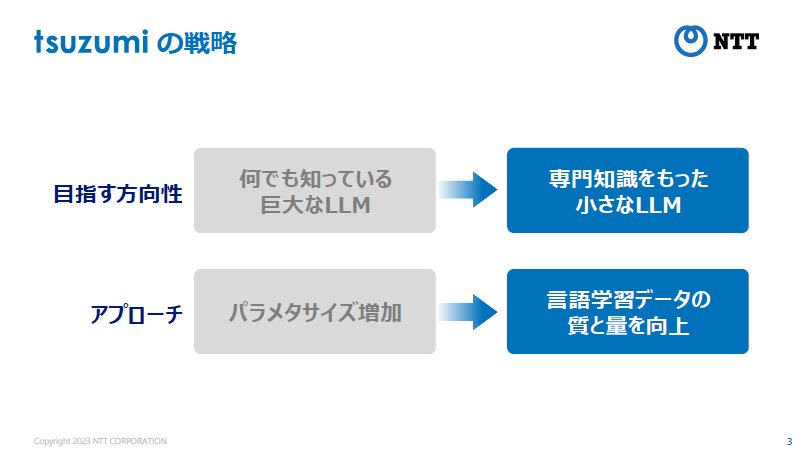 図4:tsuzumiは汎用LLMのような巨大化指向ではなく「小さな知(専門知識)の集合体」を目指して開発されている。このように専門知識に特化したLLMは、企業の生成AI活用で重要なキーワードとなりそうだ(出典:NTT)
図4:tsuzumiは汎用LLMのような巨大化指向ではなく「小さな知(専門知識)の集合体」を目指して開発されている。このように専門知識に特化したLLMは、企業の生成AI活用で重要なキーワードとなりそうだ(出典:NTT)拡大画像表示
tsuzumiのターゲットとする市場・分野は大きく2つある。1つは「クローズドデータをセキュアに学習できる」という特徴を生かせるメディカル領域やソフトウェア開発など業界特化領域で、もう1つは日本語に強く、柔軟なチューニングやマルチモーダルという特徴を生かせるコンタクトセンターや相談チャットボットなどの顧客サポート領域だ。
具体的には「電子カルテの非構造化データを構造化データに変換」「コミュニケータやチャットボットの応対アシスト」といった分野でのサポートが期待されており、すでに京都大学医学部附属病院や東京海上日動火災保険などがtsuzumiのトライアルを開始しているという。日本語に強いことに加え、PDF文書など図表の読み込みでも高い評価を受けていることから、今後はダイアグラムや伝票などの読み込みから構造化データへの変換といった拡張が進むことも期待される(図5)。
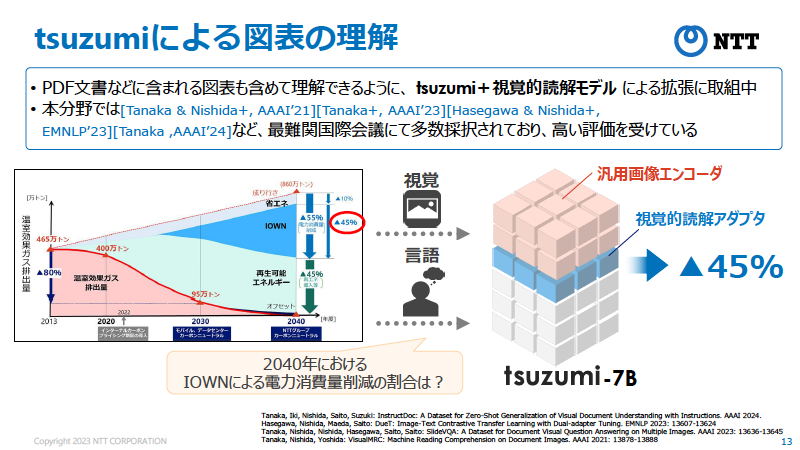 図5:tsuzumiの特徴の1つが図表の理解にすぐれていること。PDF文書などに含まれている画像なども正しく理解できるよう、視覚的読解モデルによる拡張にも取り組んでいる(出典:NTT)
図5:tsuzumiの特徴の1つが図表の理解にすぐれていること。PDF文書などに含まれている画像なども正しく理解できるよう、視覚的読解モデルによる拡張にも取り組んでいる(出典:NTT)拡大画像表示
「AWSとは以前からさまざまな協業を行ってきており、今回もその延長線上で同プログラムに参加した。40年以上に渡って自然言語処理を研究してきたNTTの知見を生かしつつ、(特徴ある音を奏でる鼓のように)たくさんの小さな言語モデルが手を取り合って、お客様のビジネスで成果を出していく、そんな世界を実現していきたい」(西田氏)へ
●Next:「企業ユーザーは誤情報の出力を嫌がる」─ハルシネーションを抜本的に解消するために独自LLMを開発
会員登録(無料)が必要です


- 1
- 2
- 3
- 4
- 次へ >
AWS / 生成AI / 大規模言語モデル / NTT / tsuzumi / リコー / ベンチャー / SI / R&D / ハルシネーション / プロジェクト管理 / Llama / NVIDIA / GPU / 自然言語処理