ビッグデータからData Lake(データの湖)へ、そしてAnalytics3.0へ−−。こんなデータアナリティクスのこれからが、米テラデータ(Teradata)のユーザー企業組織が主催するカンファレンス「PARTNERS 2014」で明らかにされた。同カンファレンスで紹介されたテラデータの最新ソリューションを紹介する。Data Lakeに挑むITの姿を象徴しているからだ。
「ITインフラ、ソフトウェア、データ。企業ITを構成する3要素の中で、最も重要かつ価値が高いのは何か?」
この問いかけへの答が「データ」であることに異論を持つ人は少ないだろう。クラウドコンピューティングによりITインフラやソフトウェアの価値は相対的に低下。一方で潜在的な顧客ニーズの把握や新たな施策の立案、問題の原因究明、今後起きうることの予測などは、いずれもデータに依存するからだ。
では、次の問はどうだろう。
「あなたが所属する企業あるいは組織は、データの価値を十分に引き出し、享受しているか?」
自信を持って「Yes」と答えられる人は、多くはないはずだ。取引や決済の履歴データはともかく、顧客とのコンタクト履歴やWebのアクセスログ、機械などモノに関わるデータ、あるいは外部の組織が提供するデータなどなど。級数的に増加するデータに対して、それを活用するための組織体制やIT環境、手法が追いついていない。多くの場合、何からどう着手すればいいのか、その手がかりすらないのが実情かも知れない。
このような問題に対し、情報を共有したり議論したりする場を提供するのが米テラデータのユーザー企業組織が主催するカンファレンス、「PARTNERS」である。2014年は10月19日〜23日に米テネシー州ナッシュビルで開催された。
参加者数は米国を中心に世界各国から4000人強(日本からは約40人が参加)。DWH(Data Warehouse)/ビッグデータがテーマとはいえ、テラデータという分野特化型のいささか地味なベンダーの、それもユーザー組織が主催する点を考えれば、かなりの規模だろう。
期待に違わず、PARTNERS2014では多くの示唆を得られた。「ビッグデータと言われて久しいが、米国企業は本当にそれを分析・活用しているのか」「だとすれば、どんな分析環境を有しているのか」「構造化データと非構造データを統合したこれからのデータ分析(Analytics)環境はどんな姿か」といった点に関して、ある程度知ることができたからである。
以下では、PARTNERS2014において、米テラデータが発表した新技術や新製品を紹介する。基調講演で語られたことや、展示会に見るビッグデータ関連ツールの動向などについては別の記事で報告する。
「構造化データ+ビッグデータ」から「Data lake」へ
まず米テラデータのDWH/ビッグデータに関する製品や考え方、それを強化するべく同社が今回発表した製品や技術を紹介しよう。最新のビッグデータに関わる技術が集約されていると同時に、基調講演のメッセージを紐解く意味でも欠かせないと考えるからだ。重要なキーワードが「Data Lake(データの湖)」である。
まず図1を見て頂きたい。テラデータが提唱する「UDA(Unified Data Architecture)」を筆者なりに解釈し、まとめたものだ(関連記事『日本テラデータが新アーキテクチャと関連製品を発表、構造化/非構造化データをシームレスに分析可能に』)。
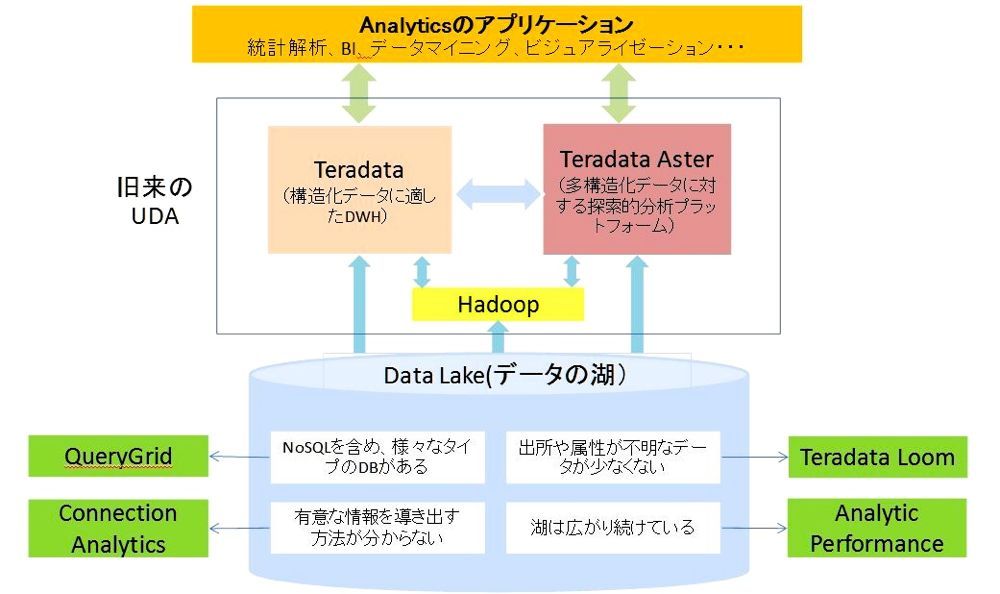 図1:「UDA(Unified Data Architecture)」の全体像
図1:「UDA(Unified Data Architecture)」の全体像拡大画像表示
UDAはArchitectureとあるが、必ずしも特定の構造や基本設計のことではない。「明確な構造を持つリレーショナル・データだけではなく、Webログやマシン生成のデータ、画像データといった非構造データも、同じように分析可能にする仕組み、あるいはそれを可能にすること」といった、ある種の考え方である。
余談だが、テラデータは「どんなデータも何らかの構造を持つ」という理由から「非構造」という言葉は使わず、「多構造(Multi-Structure)データ」と呼んでいる。
少し前まで、UDAは図1の上半分を対象にしていた。構造化データはデータウェアハウスの「Teradata」で、Hadoop上に蓄積される非構造のビッグデータは「Teradata Aster」というソフトウェアで、それぞれ処理する(いずれもハードに組み込んだアプライアンス製品がある)。
ここで、「ビッグデータを処理するのがHadoopのはず。なぜAsterが必要なのか」という疑問がわくかも知れない。確かにHadoop(テラデータの場合は提携する米Hortonworksのディストリビューション)は、MapReduceというデータの抽出や整形の仕組みを備える。しかし、使いこなすにはJavaでプログラムを書く必要があり、一般には難度が高い。
そこでAsterの出番になる。Asterは広く普及しているデータ操作言語「SQL」でMapReduceの処理ができるよう、MapReduceでよく使われる処理70種を関数の形で備える。SQL文に関数名を記すだけで、非構造データを処理できる。このようなSQLを介して非構造データを扱う方式は、現在では米SAS Instituteや米Oracleなども提供しており、急速に普及しつつある。
Data Lake(データの湖)から“飲み水”を生み出す
ところがデータ量の爆発的増大が見込まれる今、このような狭いUDAでは不十分な状況が生まれている。その要因が最近、少しずつ聞かれるようになった概念「Data Lake」である(図1の下部中央)。Data Lakeは「いわゆるData Martをペットボトルとすれば、Data Lakeは水源である。様々な川から流れ込む水が溜まる湖のようなものだ」と説明される。
B2C(Business to Consumer:企業対個人)かB2B(Business to Business:企業間)かによって多少の違いはあるが、企業は日々の取引データや業務ファイル、IT機器のログやWebサイトのアクセスログ、監視カメラの画像データなど、大量のデータを蓄積している。
そこに今後は、工場の生産機械などのセンサーデータや、保有する車両の位置データ、さらには外部のソーシャルデータやオープンデータも加わる。それぞれ出所もフォーマットも、ボリュームも異なるが、企業が扱うべきデータの一部であることは間違いない。その集合体をData Lakeと呼ぶわけである。
必然的にデータ分析の対象は特定の業務データやビッグデータでは済まず、Data Lakeになる。ではData Lakeから自由にデータを取り出し、分析するためには何が必要か?テラデータが今回、発表したのは、実のところ、そのための製品や技術だった(図1の緑の部分)。
まずLakeの中には様々なDBMS(DataBase Management System)がある。それにアクセスして必要なデータを抽出するための新機能が「QueryGrid」である(図2)。単一の問い合わせで複数のDBMSに同時にアクセスでき、その際、DBMS側でデータを処理することで転送量を減らす。大量データの転送には、不可欠な工夫だ。
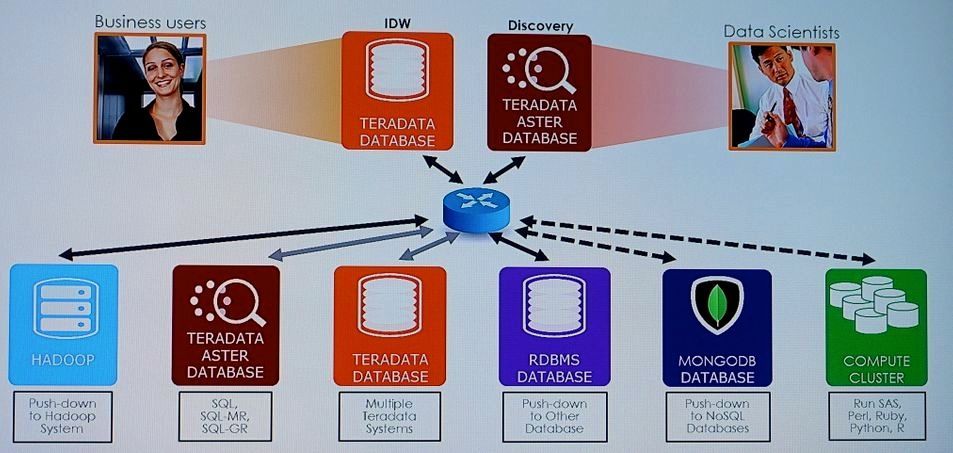 図2:必要なデータを抽出する「QueryGrid」
図2:必要なデータを抽出する「QueryGrid」拡大画像表示
QueryGridでアクセスできるDBMSは、NoSQL型ではMongo DBやHbase、cassandraなど、SQL型ではOracleに対応している。そのほかのDBMSにも順次対応していく。
Oracle上のデータに関してはTeradataに転送せずに利用できる仕組みもある。転送N対Nのデータ転送をサポートするという意味で、テラデータはQueryGridを「データファブリック」と呼ぶ。2015年出荷予定の次期Teradataに実装する予定である。
会員登録(無料)が必要です


- 1
- 2
- 3
- 次へ >
























