東京大学と日立製作所は2018年11月20日、大規模データの匿名加工処理を高速化する技術を共同で開発したと発表した。日立製作所は、2019年度中にデータベースソフト「Hitachi Advanced Data Binder」に同技術を組み込む。
今回開発した技術は、匿名加工処理の手続きをデータベース上の演算として定義する。非順序型実行原理に基づくデータベースエンジン上で、匿名加工処理を直接実行する。これにより、大規模データの匿名加工処理を高速化する。
非順序型実行原理は、データの要求順序とは無関係な順序に非同期的にデータを処理することによって、ハードウェアの処理性能を最大限に引き出すというもの(図1)。東京大学生産技術研究所と日立製作所は、同原理を取り入れたデータベースエンジンを開発した。
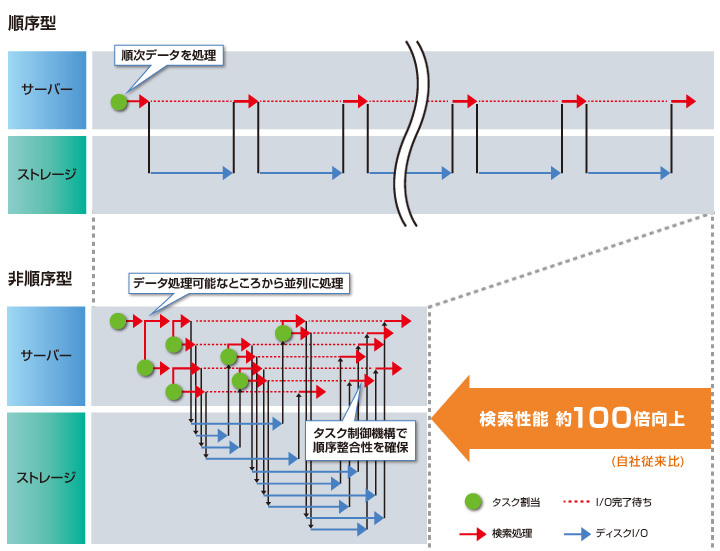 図1:非順序型実行原理の仕組み(出典:日立製作所)
図1:非順序型実行原理の仕組み(出典:日立製作所)拡大画像表示
従来、匿名加工処理は、専用ソフトを用いるやり方が一般的だった。データベースから対象となるデータを抽出してから、専用ソフトを用いて匿名加工処理を行っていた。このため、大規模データに匿名加工処理を実施することは困難だった。
東京大学生産技術研究所は、ベンチマーク用データセットを用いて、非順序型実行原理を採用したデータベースエンジンと、従来のデータベースエンジンを比較した。この結果、100倍程度に高速化できることを確認した。
匿名加工処理を高速化できることから、匿名加工処理を施したデータの安全性や有用性の検証までを短時間に行えるようになった。必要に応じて匿名加工処理や検証の再実行を繰り返し行うという対話的な処理が可能になった。
データの匿名加工処理においては、例えば同じ属性を持つデータが一定数以上存在するようにデータを変換し、個人が特定される確率を低減するといった措置を行う。しかし、このような匿名加工処理の過程では情報が失われる可能性があり、有用な情報量を確保するためには、データの抽出範囲や加工単位などを細かく調整しながら、データの検証を繰り返す必要がある。このため、データの規模や種類が増えるほど、匿名加工処理に費やす時間が膨大になるという課題があった。
なお、今回の共同開発は、内閣府総合科学技術・イノベーション会議が主導する革新的研究開発推進プログラム「社会リスクを低減する超ビッグデータプラットフォーム」の支援の下で実施した。