[技術解説]
対話型AIは「知的なかな漢字変換」、人間に近い知的エージェントになる─NTTデータ先端技術の城塚音也氏
2023年3月9日(木)日川 佳三(IT Leaders編集部)
NTTデータ先端技術は、AIサービスの開発などに取り組んでいる。2023年3月9日、JDMC主催の「データマネジメント2023」の基調講演に登壇した同社ソフトウェアソリューション事業本部デジタルソリューション事業部AIソリューション担当Principal Scientistの城塚音也氏は、対話型AIなどに使われる大規模言語モデルの動向と、これらを仕事や社会で活用していくうえで解決しなければならない課題、および解決方法を解説した。
 写真1:NTTデータ先端技術 ソフトウェアソリューション事業本部 デジタルソリューション事業部 AIソリューション担当 Principal Scientistの城塚音也氏
写真1:NTTデータ先端技術 ソフトウェアソリューション事業本部 デジタルソリューション事業部 AIソリューション担当 Principal Scientistの城塚音也氏 NTTデータ先端技術の城塚氏(写真1)は、AIサービスの開発などに取り組んでいる。城塚氏は講演で、生成AIを中心とした現在のAIの状況、ChatGPTなどの対話型AIが登場した背景、対話型AIの課題と解決の方向性、社会的問題などを解説した。
「AIの進化ペースは速い」と城塚氏は指摘する。AI関係の論文の数は、23カ月ごとに2倍に増えており、現在は月4000本の論文が書かれている。AIへの期待もポジティブであり、2022年5月から6月にかけて自然言語処理の専門家480人に聞いたアンケートでは、AIが「革命的な社会変革」だと捉えた人は73%を占めたという。
実際に、AIの進化は著しい(図1)。城塚氏は、いくつか例を挙げた。大規模言語モデルは、用途ごとのチューニングを必要とすることなく、多くのタスクをこなす。対話型AIは自然な文章を生成し、画像生成AIはテキストから画像を生成する。マルチタスクロボットは、人間の曖昧な言葉だけで取るべき行動を決定する。
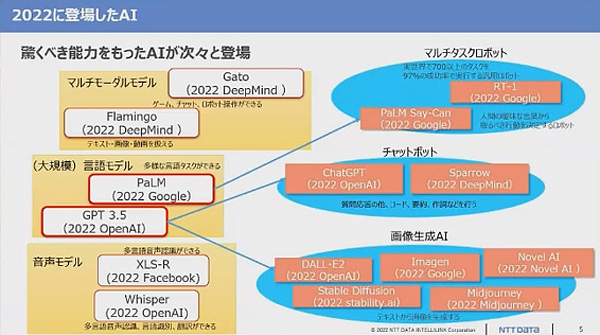 図1:2022年に登場した主なAI(出典:NTTデータ先端技術)
図1:2022年に登場した主なAI(出典:NTTデータ先端技術) 特に、2022年11月に公開された米OpenAIのChatGPTは、大きな話題になった。大規模言語モデルのGPT3.5をベースに会話向けにチューニングしたものである。文章生成の精度は、米国の大学院や弁護士、医師などの試験問題に合格するようなレベルだと城塚氏は指摘する。米マイクロソフトは100億ドルの投資を決定し、検索エンジンのBingなどに採用した。
城塚氏が実際にChatGPTに「データの迷宮から脱出するにはどうすればいいでしょうか」と聞いてみたところ、データマネジメントの手順を説明してくれたという。目的を明確にする、データの品質を確認する、データの整理と前処理を行う、モデルを構築し、評価を行う、といったことを教えてくれたという。「迷宮から脱出するといった比喩的な質問に対しても回答している」(城塚氏)。
Transformerを使った言語モデルが精度で人間を上回る
講演の前半では、ChatGPTが登場した背景を説明した。自然言語処理の中に言語理解があり、言語理解では、「検索」「分類」「抽出」「生成」の順に、難易度が上がる。現在では、最後の生成のレベルまで実用化されている。
言語理解はもともと、文脈に応じた単語の意味の違いを捉えることができなかった。文は単語の集まりであり、単語が1つの袋の中にたくさん入っている、というモデルだった。2000年以降、ニューラルネットが進化したことで状況が変わった。文脈の違いで単語の意味を捉えるようになった。
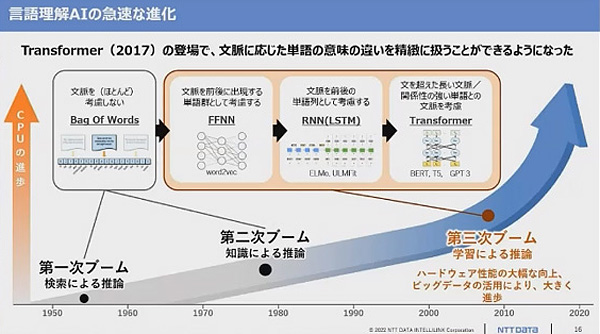 図2:Googleの言語モデル「Transformer」により、文脈に応じた単語の意味の違いを精密に扱えるようになった(出典:NTTデータ先端技術)
図2:Googleの言語モデル「Transformer」により、文脈に応じた単語の意味の違いを精密に扱えるようになった(出典:NTTデータ先端技術) 2017年に米グーグルが発表した言語モデル「Transformer」の功績が大きい(図2)。現在の大規模言語モデルでも使われている。Transformerを使った言語モデルのBERTは、Wikipediaのテキストと質問を与えて答えを抽出するテストにおいて、人間の精度を上回ったという。例えば「降水の原因は何か」との問いに「重力」と答える、といったテストである。
Transformerベースの言語モデルは、精度を高める方法として、大量のテキストデータから問題を作って自己学習している。例えば、テキストから単語を欠損させて、欠損部分に何が入るかを予測する穴埋め問題である。また、2つの文が継続した文なのか継続しない文なのかという問題を作って解く。これらの問題を大量に解く。次に、ニューラルネットにおいて、個々のタスクに合わせた出力層を作り、少量のデータセットを用いてファインチューニングを行う。これにより、複数のタスクをこなせる言語モデルが完成する。
言語モデルの精度は、学習のスケールを高めることによって向上させられる。1つは、学習するデータの量を増やすこと。2つ目は、言語モデルのサイズ(規模)を大きくすること。3つ目は、学習の演算量を増やすこと、である。
言語モデルの規模が100億パラメータ以上のTransformerモデルを大規模言語モデルと呼ぶ。代表的な大規模言語モデルに、Google T5(2019年)やGPT-3(2020年)がある。GPT-3は1750億パラメータ(BERTは数億程度)で、1兆語、45TBのテキストデータを学習している。
大規模言語モデルは複数のタスクをこなせる
大規模言語モデルの特徴について城塚氏は、超大規模なテキストデータを学習することで、多様なタスクをこなせるようになったことだと説明する。この結果、数例の事例を与えるだけで回答が得られるモデルになった。
例えば、グーグルが2022年に公開した言語モデルのPaLMは、150種類の推論タスクの平均スコアが、平均的な人間を超えたという。タスクごとのチューニングはせず、150種類それぞれについて数例の実例を見せるだけで、人間を超えたという。PaLMでは、あるジョークを提示して、そのジョークがなぜ面白いのかを解説できる。算数の文章題も解ける。
城塚氏によると、2020年以降、Transformerを利用した言語モデルの応用が急速に進化・拡大している。例えば、視覚言語モデルのCLIPは、4億枚の画像とキャプションを学習しており、テキストから画像を生成するほか、画像からテキストを生成する。
グーグルの対話型AIのLaMDAは、特定の役を演じることが可能である。「あなたは冥王星です」というシチュエーションを与えると、冥王星になり切って会話をしてくれる。「あなたのところに行ったら何が見えますか」と聞くと「巨大な峡谷や凍った氷山、間欠泉、クレーターなどが見えます」などと答えてくれる。
DeepMindが2022年に出したGatoは、異なる複数の仕事を、たった1つのモデルでこなす。ビデオのゲームをプレイしたり、チャットボットになったり、画像にキャプションをつけたり、ロボットアームを操作したりできる。
●Next:対話型AIが抱える課題と、それぞれの解決策
会員登録(無料)が必要です


- 1
- 2
- 次へ >
大規模言語モデル / 対話型AI / ChatGPT / NTTデータ先端技術 / R&D / Transformer / Google / OpenAI / Bing / Microsoft / 自然言語処理 / ディープラーニング / BERT / PaLM / GPT / JDMC / 生成AI