[新製品・サービス]
ELYZA、商用利用可能な130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」を公開
2023年12月27日(水)日川 佳三(IT Leaders編集部)
ELYZA(イライザ、本社:東京都文京区)は2023年12月27日、130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」の一般公開を開始した。Llama 2 Community Licenseに準拠し、研究だけでなく商業目的での利用が可能である。同社独自の性能評価では、1750億パラメータのGPT-3.5(text-davinci-003)の性能を上回るという。
東京大学松尾研究室発のAIスタートアップであるELYZA(イライザ)が「ELYZA-japanese-Llama-2-13b」の公開を開始した。130億パラメータの日本語大規模言語モデル(LLM)で、Llama 2 Community Licenseに準拠しており、研究だけでなく商業目的で利用できる。
ELYZAが独自に作成・公開している日本語LLMベンチマーク「ELYZA Tasks 100」の性能評価では、1750億パラメータのGPT-3.5(text-davinci-003)の性能を上回っている(表1)。
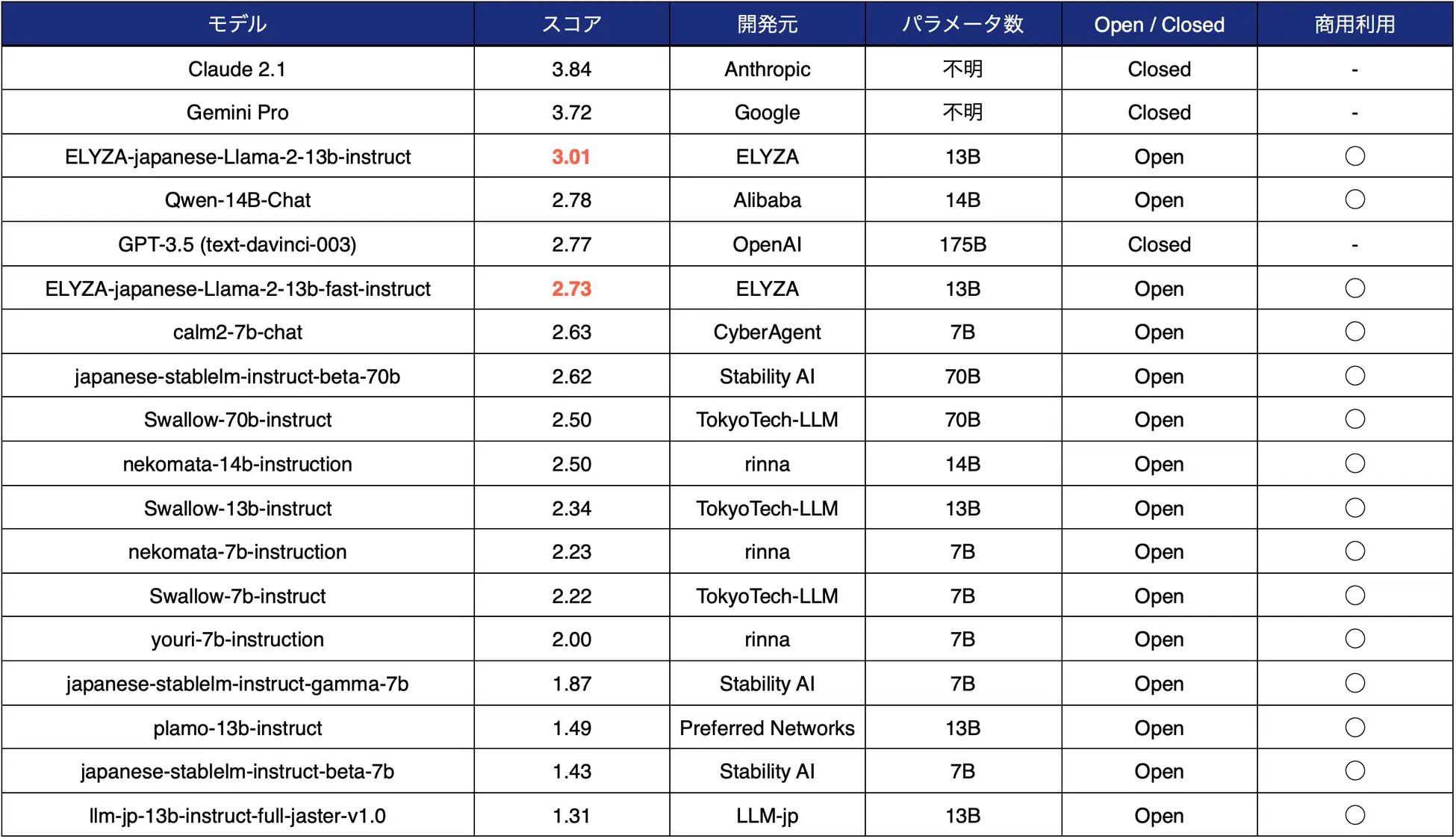 表1:ELYZAの日本語ベンチマーク「ELYZA Tasks 100」によるLLMの性能評価。1750億パラメータのGPT-3.5(text-davinci-003)を上回った(出典:ELYZA)
表1:ELYZAの日本語ベンチマーク「ELYZA Tasks 100」によるLLMの性能評価。1750億パラメータのGPT-3.5(text-davinci-003)を上回った(出典:ELYZA)拡大画像表示
米Meta PlatformsのLLM「Llama-2-13b-chat」をベースに、約180億トークンの日本語テキストデータ(OSCARやWikipediaなどにある整理された日本語テキストデータ)で追加事前学習を実施。学習処理は、産業技術総合研究所(産総研)が運用する「AI橋渡しクラウド(ABCI)」で行っている。ABCI上では700億パラメータモデルの開発も進めているという。
ELYZA-japanese-Llama-2-13bには複数のバリエーションがある。ユーザーの指示からさまざまなタスクを解くことを目的に、ELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-13b-instruct」、日本語の語彙を追加して高速化を図った「ELYZA-japanese-Llama-2-13b-fast」を挙げている。各モデルの詳細を同社の技術ブログで説明している。なお、表1にある1750億パラメータのGPT-3.5の性能を上回るスコアは2-13b-instructのものである。
なお、2-13b-fastには、2023年8月公開の前モデル「ELYZA-japanese-Llama-2-7b-fast」で作成したトークナイザーをさらに効率化する改良を加えている。前モデルの1万3042個よりも少ない1万2581個の日本語の語彙を追加して、同じ日本語の文章を表すのに必要なトークン数を「Llama 2」の47%に削減した(前モデルは55%削減)。推論速度換算で約2.27倍の性能にあたるという。
ELYZAは、2-13bの公開に伴い、体験可能なデモを示している。デモ環境はNVIDIA A100 GPUで、「vLLM」ライブラリを用いて推論を高速化し、その効果を最大限体感できるようにしたという(画面1)。
 画面1:デモで公開している、ELYZA-japanese-Llama-2-13b-instructによるチャット画面の出力例(出典:ELYZA)
画面1:デモで公開している、ELYZA-japanese-Llama-2-13b-instructによるチャット画面の出力例(出典:ELYZA)拡大画像表示