AI学習データの作成サービスを提供するバオバブは2024年1月17日、生成AI/大規模言語モデル(LLM)をRAG(Retrieval-Augmented Generation)構成で利用するためのデータセットを構築するSIサービスを開始した。RAG用データセットのサンプルデータ配布と合わせて提供する。
バオバブは、生成AI/大規模言語モデル(LLM)をRAG(Retrieval-Augmented Generation:検索拡張生成)構成で利用するためのデータセットを構築するSIサービスを開始した。
RAGは、LLMと外部のナレッジベースを組み合わせて得る情報を、ユーザーのコンテキストや入力するプロンプトと併用する手法である。生成AIの誤回答を回避しながら、適切な情報が存在しない場合はその事実を回答できるようになる。
「LLMには、専門知識や非公開情報、事実性が重要視されるコンテキストにおいて、時に作話や不正確な情報を提示してしまうハルシネーションの問題がある。これは生成AIの導入を検討する企業にとって懸念点で、RAGはこれを解決する有効策である」(バオバブ)
バオバブのサービスでは、RAG実行のためのプロンプト設計とデータセットを構築する。合わせて、LLM構築のコンサルティングを提供する。RAG用データセットには以下の要素が含まれている。
- ユーザーの質問文
- 知識源からユーザーの質問に合致する情報を抽出するクエリー
- 知識源から抽出された情報
- 言語モデルの回答文
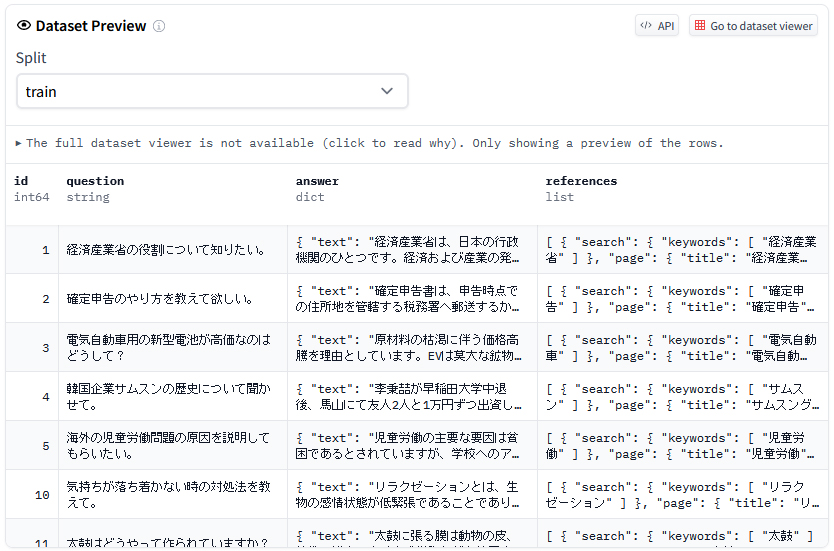 画面1:RAG用データセットのサンプル表示画面(出典:バオバブ)
画面1:RAG用データセットのサンプル表示画面(出典:バオバブ)拡大画像表示
RAG用データセット構築サービスの提供開始に合わせて、RAG用データセットのサンプルデータを無料で配布する。WikipediaをナレッジベースにしたQ&Aデータセットで回答数は1150件。12日間かけて作成したという(画面1)。