データサイエンティストなど、データ分析・活用で高度なスキルを持つ人材の獲得がきわめて困難になっている。そんな中、専門家を雇わずとも、高度なマシンラーニング(機械学習)の利用を可能にすると謳うツールが相次いで登場している。その1つが米国のソフトウェアベンダー、H2O.aiの「Driverless AI」だ。実際、どんなことができるのかを、日本で同製品を販売するマクニカネットワークス米国法人の責任者に聞いた。
「データから価値を導出する」「これからはデータ駆動ビジネスだ」──もはやおなじみのフレーズだ。過去の実績を分析して何が起きたか、起きているかを可視化する程度なら、BI(ビジネスインテリジェンス)ツールを使えばそれなりの結果を出せる。しかし、将来の需要を予測したり、故障を検知したりといった、いわゆる予測分析(Predictive Analytics)となると話は別で、簡単ではない。
マシンラーニングの導入で待ち受けるハードル
マシンラーニングを用いた予測分析に着手するとして、ハードルはいくつもある。まず、分析対象になるデータのプレパレーション(Preparation:整備)が必要だ。検査してみると、ある時期のデータが欠落していたり、データ項目に抜けがあったり、間違いや異常値があったりする。文字列をコードに置き換える必要もある。
地味で時間がかかるデータプレパレーションを終えた後には、データサイエンスやマシンラーニングの核心と言える「特徴量エンジニアリング(Feature Engineering)」が待ち受ける。例えば、ある商品の需要を予測する場合に、地域や時間、価格、併売する商品などさまざまなデータ項目からどの項目群が予測に効くのかを選んだり、加工して新しい項目を作り出したりする作業である。
各項目は複雑に絡み合う。項目同士の関連を読み解き、適切な特徴量を抽出するには、ビジネスや業務、および扱うデータに関する専門知識が必要になる。しかし、ディープラーニングは別にして、特徴量エンジニアリングは通常、マシンラーニング(ソフトウェア)に任せることはできず、試行錯誤しながら人間がセットしなくてはならない。
特徴量エンジニアリングが終わったら、ようやくデータの学習だ。あまたあるマシンラーニングのアルゴリズムから適切なものを選び、学習させることになる。そこではどんなアルゴリズムが適するのか試行錯誤が欠かせないし、収集するデータの種類が増えれば仕事はどんどん増えていく――。こうした一連のハードルが、データサイエンティストが必要な理由であり、企業でデータの高度活用の成果を生み出しにくいゆえんでもある。
「データサイエンティストいらず」は本当か
しかし最近になって、この難題をクリアすると謳う製品が増えている。米国発で日本でもじわじわとユーザーを増やしている米データロボットの「DataRobot」、NECが米国に専門企業ドットデータを設立して開発を進める「dotData」、データプレパレーションに強みを持つ米アルタリクスの「Alteryx」、日本には未参入だがMIT(米マサチューセッツ工科大学)をルーツとするスタートアップ、米フィーチャーラボの「Feature Labs」、2018年11月にマクニカネットワークスが提携、国内で販売が始まる米H2O.aiの「Driverless AI」などである。
これらの製品は本当に「データサイエンティストいらず」なのか。H2O.aiを扱う米マクニカの幹部に話を聞く機会があったので、Driverless AIの仕組みを詳しく確認してみる。日本ではまだほとんど知られていない同社だが、海外ではオープンソースのAIプラットフォーム「H2O」を提供する有力ベンダーという評価を得ている。多くは無料版と考えられるが、H2O.aiによるとフォーチュン500のほぼ半数の企業を含めて、世界1万4000社で利用されているという(関連記事:マクニカ、機械学習を自動化するソフト「Driverless AI」を提供、判定理由も可視化/「機械学習は数千種に及ぶアルゴリズムからの選択がカギ」―マクニカ、海外最先端AIソリューションの提供体制を整備)。
Driverless AIは、H2O.aiが2017年春にリリースした、OSSではない初の商用製品だ。米マクニカ バイスプレジデントのAvkash Chauhan氏(前職はH2O.aiのバイスプレジデント)によると、製品名はドライバーによる運転を不要にする自動運転車から着想したネーミングで、「自動運転と同様に、だれもが高度なデータ分析をできるようにするために、データサイエンテイストが行う必要があるマシンラーニングモデル作成業務を自動化する」(同氏)という。ただし、同製品のカバー範囲は特徴量エンジニアリングからモデル作成までで、その前段階であるデータプレパレーションは別途行う必要がある(図1)。
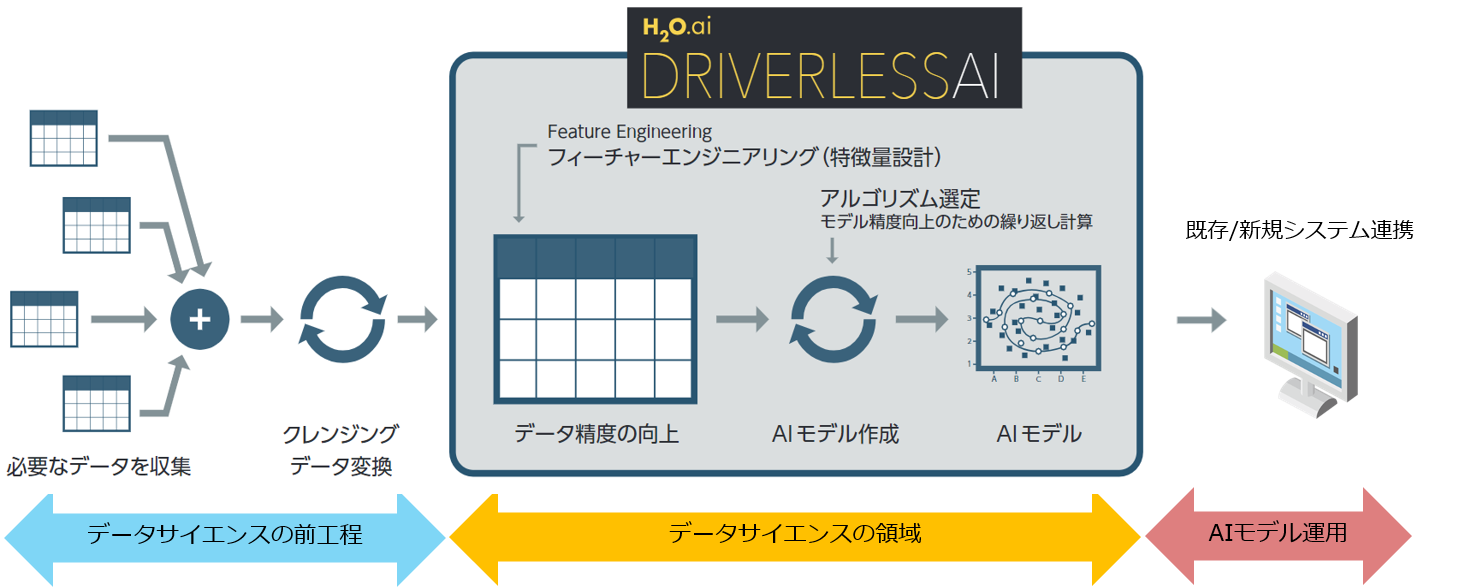 図1:一般的なマシンラーニングプロセスと「Driverless AI」のカバー範囲(出典:マクニカネットワークス/H2O.ai)
図1:一般的なマシンラーニングプロセスと「Driverless AI」のカバー範囲(出典:マクニカネットワークス/H2O.ai)拡大画像表示
会員登録(無料)が必要です


- 1
- 2
- 次へ >
マシンラーニング / マクニカネットワークス / H2O.ai / データサイエンティスト / データマネジメント / DataRobot / データプレパレーション / Alteryx / dotData