Preferred Networks(PFN)は2018年12月12日、ディープラーニング(深層学習)の学習工程を高速化する用途に特化したプロセッサ「MN-Core」を発表した。消費電力あたりの半精度浮動小数点演算性能は1ワットあたり1TFLOPS(テラフロップス)を見込む。2020年春にはMN-Coreを搭載した大規模クラスター「MN-3」を構築する。MN-3の計算速度は、最終的に半精度で2EFLOPS(エクサフロップス、1秒に200京回の浮動小数点演算)まで拡大する。
Preferred Networks(PFN)が開発するプロセッサ「MN-Core」は、ディープラーニング(深層学習)の学習工程を高速化する用途に特化したプロセッサである(写真1)。行列演算器を高密度に実装し、条件分岐がない完全SIMD動作をするシンプルなアーキテクチャとした。1つのパッケージは4ダイで構成し、ダイにつき512個、計2048個の行列演算ブロックを集積している。チップあたりのピーク性能は、深層学習でよく使う半精度浮動小数点演算で524TFLOPS(1秒あたり524兆回)。
 写真1:ディープラーニング(深層学習)の学習工程を高速化する用途に特化したプロセッサ「MN-Core」の外観(出典:Preferred Networks)
写真1:ディープラーニング(深層学習)の学習工程を高速化する用途に特化したプロセッサ「MN-Core」の外観(出典:Preferred Networks)拡大画像表示
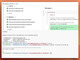
特徴は、電力性能(消費電力あたりの演算性能)を高めたことである(表1)。半精度浮動小数点演算において、世界最高クラスの1ワットあたり1TFLOPS(1秒あたり1兆回)を実現できる見込みとしている。最小限の機能に特化することで、コストを抑えながら、深層学習における実効性能を高めることが可能である(関連記事:ディープラーニングでデバイスの制御にまで踏み込む─Preferred Networksが事業を説明)
| 製造プロセス | TSMC 12nm |
|---|---|
| 消費電力(ワット、予測値) | 500 |
| ピーク性能(TFLOPS) | 32.8(倍精度) 131(単精度) 524(半精度) |
| 電力性能(TFLOPS/ワット、予測値) | 0.066(倍精度) 0.26(単精度) 1.0(半精度) |
●Next:MN-Coreの提供形態と今後の拡張計画
会員登録(無料)が必要です


ディープラーニング / プロセッサ / Preferred Networks / GPU / GPGPU / MN-Core / スーパーコンピュータ