NTTデータは2019年8月29日、Apache Kafkaによる大規模データのリアルタイム処理を支援するSIサービス「Kafka構築・運用ソリューション」を発表、同日提供を開始した。Kafkaによって、センサー情報や位置情報などをリアルタイムに活用するシステムを容易に構築できるとしている。同サービスの売上目標は、今後3年間で累計100億円。
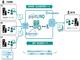
Apache Kafkaは、大規模なIoTセンサーデータやログデータ、監視データなどを高速に取り込んでキューに溜め、これを配信する、オープンソースの分散メッセージング基盤ソフトである。常時発生する“ストリーミングデータ”を、滞りなくシステムからシステムへと受け渡すための、データパイプラインとして機能する。
従来、センサーなどにおいて随時生成される大規模データを受け渡すためには、各システムで個別に設計・構築を行う必要があった。Apache Kafkaを使うと、大規模データを受け渡してリアルタイムに処理するシステムを、より容易に実現できる。例えば、GPSや速度センサー情報から渋滞を考慮して経路を案内したり、金融取引の不正をリアルタイムに検知したりできる。
NTTデータは以前から、オープンソースの大規模データ処理基盤であるApache HadoopやApache Sparkを活用した「Hadoop/Spark構築・運用ソリューション」を提供してきた。また、大規模データのリアルタイム活用ニーズの増加に合わせ、独自にApache Kafkaを検証し、商用システムを利用・運用するための知見を蓄積してきた。
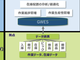
NTTデータは今回、Apache Kafkaの検証で培った知見を生かし、「Kafka構築・運用ソリューション」をメニュー化した。Apache Kafkaを活用して大規模データのリアルタイム処理基盤を実現できるように、コンサルティング、実証実験、基盤構築、運用まで、一通りの技術サポートを提供する。
Kafka構築・運用ソリューションの特徴の1つは、サーバー台数を抑えて分散メッセージング基盤を構築できること。Apache Kafkaが標準で備える耐障害性の仕組みを最大限に活用し、独自に検証した耐障害性の方式を併用することで、標準のApache Kafkaと比べて少ないサーバー台数で基盤を実現する。
もう1つの特徴は、ユーザーの利用環境や要件に応じて、データ活用基盤全体のコンサルティングやシステム構築を提供すること。システム要件や将来の拡張性を考慮して基盤のアーキテクチャを検討する。また、Hadoop/Spark構築・運用ソリューションと組み合わせ、大規模データのバッチ処理基盤も含めてデータ活用基盤の全体を構築できる。
さらに、専門技術者によるサポートを提供する。システム構築・運用時の疑問点やトラブルなどの問い合わせに回答する。Hadoop/Spark構築・運用ソリューションで提供しているHadoop/Sparkサポートサービスとの併用も可能である。全ての問い合わせには、ソースコードの解析ができる専門技術者が対応する。導入後の運用が長期間となった場合でも、継続的なサポートサービスの提供が可能である。