NTTデータは2020年7月10日、金融版BERTを用いた自然言語処理技術に関して、銀行や証券会社などの金融関連企業を募り、2020年7月以降順次、実証検証を開始すると発表した。自然言語処理により、財務情報からリスクを抽出したり、チャットボットを用いて問い合わせに対応したりできる。2020年度に5件の実証検証を行い、2021年度中にサービス提供を開始する。
金融版BERTは、AIを用いた自然言語処理技術のBERT(Bidirectional Encoder Representations from Transformers)を、金融業界向けにNTTデータが独自に特化させた言語モデルである。金融版BERTを使うと、金融専門用語や特有の文脈を含む文書を解析する際に、その都度言語モデルの学習を行う必要がなくなる。学習工程を短縮し、高精度の結果を得られる。
BERTの特徴は、従来の自然言語処理技術では難しかった、文脈を踏まえた解析が可能になること。金融版BERTが想定する主な業務は、日報からの情報抽出、稟議書の記載内容チェック、財務情報からのリスク抽出、コールセンターにおけるFAQ(よくある問い合わせと回答)の回答自動引き当て、チャットボットによる問い合わせ対応などである。
その背景についてNTTデータは、金融業界においても、チャットボットによる顧客対応や審査などに自然言語処理技術を活用している状況を挙げる。「一方で、金融業界の文章は、業界特有の専門性の高い用語や言い回しが多く、辞書整備や多数のルール構築が必要になるなど、自然言語処理技術を適用する負荷が高かった。また、そもそも大規模なコーパスで学習させた日本語モデルが少ないという課題もあった」(同社)。
BERTを開発した米グーグルが発表したBERTモデルは、13GB以上のコーパスで学習させたものである。一方、公開されている日本語向けBERTモデルの大半は、日本語Wikipediaコーパス(3GB程度)で学習させたものだった。そこで、NTTメディアインテリジェンス研究所が、日本語Wikipediaに加えてニュースサイトやブログから収集した大規模コーパス(12.7GB)を用い、日本語BERTモデル(NTT版BERT)を開発した。
金融版BERTは、NTT版BERTをベースに、NTTデータが独自に収集した金融関連文書を用い、金融文書向けに追加学習したモデルである(図1)。特定分野のコーパスで学習させたBERTモデルは、その分野のタスクにおいては、一般的なコーパスで学習させたBERTモデルより高い精度が出る。
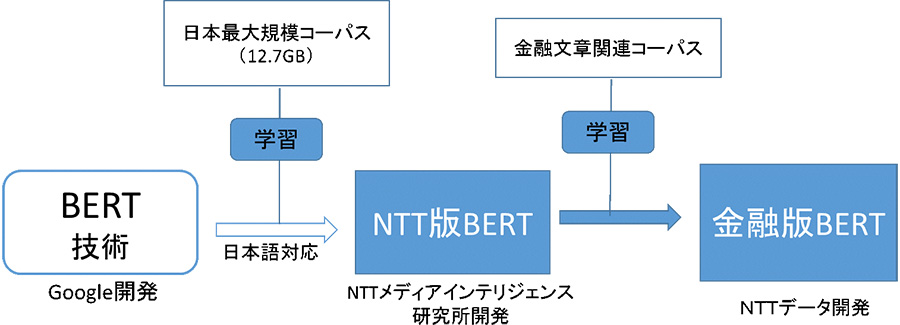 図1:金融版BERTのイメージ図(出典:NTTデータ)
図1:金融版BERTのイメージ図(出典:NTTデータ)拡大画像表示