2010年代に入ってから、ビッグデータが多くの企業から注目されている。その理由は、ビッグデータを活用することで、同業他社との差別化を図り、売上拡大や業務効率化により企業価値を向上させることができるからである。ビッグデータを蓄積/処理する基盤としてDWH向けRDBMSやHadoopがあり、成り立ちやアーキテクチャは異なるが、データを格納して、SQLをインタフェースとしてデータにアクセスすることができる点など、利用者から見ると違いが分かり難くなってきている。そこで日本ユニシスでは、DWH向けRDBMSとHadoopを用いて、データロード、データ検索について性能面での比較検証を行い、SQL on Hadoop(Hadoop内のデータをSQLで処理する機能)の適用範囲について考察を行った。本稿では検証結果と考察を報告する。
※本稿は日本ユニシス発行の「技報通巻127号」(2016年3月発行)の記事に加筆・編集して掲載しています。
2011年に米国の調査会社McKinsey & Companyの研究部門であるMcKinsey Global Instituteが発表したレポート「Big data: The next frontier for innovation, competition, and productivity」によりビッグデータが注目を集めており、それ以降、本格的にビッグデータの活用に取り組む企業が増えてきている。その理由は、ビッグデータを活用することで同業他社との差別化を図り、売上拡大や業務効率化により企業価値を向上させることができるからである。
スマートフォンやSNS(Social Networking Service)などの普及により、膨大かつ多様なデータが短時間に発生している。2020年には約40ZB(ゼタバイト)のデータが発生すると言われている。これらのデータを蓄積する基盤としては、データウェアハウス(以下、DWH)専用のリレーショナルデータベース管理システム(以下、RDBMS)とHadoopがある。両方とも成り立ちやアーキテクチャは異なるが、データを格納して、SQLをインタフェースとしてデータにアクセスすることができる点など、利用者から見ると違いが分かり難くなってきている。
ビッグデータが注目されている背景と課題
ビッグデータが注目されている背景
エンタープライズシステムにおけるデータ活用は、基幹系システムのデータを分析対象としていた。しかし、2011年のMcKinsey Global Instituteのレポート発表以降、スマートフォンやSNSなど基幹系システム以外のデータも分析対象とすることで、他社との差別化を図り、企業価値を向上させることができると考えられるようになった。基幹系システムのデータも含めた、企業内外に存在するあらゆるデータの総称がビッグデータであり、ビッグデータという言葉が注目を集めることとなった。
他にもビッグデータが注目されるようになった理由は2つある。1つは総務省の情報通信白書で先進企業におけるビッグデータの利用実態が公開され、ビッグデータ活用の有効性が各企業に認識されたこと。もう1つは、CPUコア数増加による性能向上やネットワーク帯域拡大など、ビッグデータ活用に必要な技術が革新的に進歩したことである。
ビッグデータの課題
これまでビッグデータが注目されている背景について述べてきたが、2015年時点でもビッグデータの活用が進んでいるとは言えない。その理由は、「投資対効果」「プライバシー・機密情報の取り扱い」「データの精度」「技術者不足」の4つの課題があるためである。
ビッグデータ活用のためには多額のIT投資が必要になるが、投資対効果の算出が難しく、経営層の承認を得るのが難しい。また、ビッグデータ活用を始めたとしても、プライバシー、機密情報への抵触を避けるために、データの活用が進まないことや、収集したデータの精度が悪く、意図していた活用ができないこともある。
さらに、RDBMS以外のデータベース管理システムであるNoSQLや、大量のデータを複数のサーバーで分散管理して並列に処理するインメモリデータグリッドなど新しい技術が次々と出てきても、対応できる技術者は、育成が進まず慢性的に不足している。
技術者の不足については、HadoopなどでのSQLインタフェースへの対応のように、多くの人が利用できるような機能拡張が行われている。しかし、利用者視点ではDWH向けRDBMSとHadoopのどちらを採用すべきか分かり難く、適用しても期待した性能要件を満たせない可能性がある。そうならないためには、各々のアーキテクチャや特性を理解した上で、適用を検討する必要がある。
DWH向けRDBMSとHadoopの技術動向と問題提起
DWH向けRDBMSの技術動向
DWHとは1990年代初頭にビル・インモン(William H. Inmon)によって提唱された、企業ビジネスの意思決定を支援するデータの格納庫である。DWHは基幹システムのデータを加工して取り込み、目的別にデータマートを作成していた。また、DWHの実装にはOracle、SQL Server、DB2などの汎用RDBMSが採用されていた。しかし、汎用RDBMSでは、大量データを扱うには大量のコンピュータリソースを搭載した高価なハードウェアが必要となるため、限られた企業のみが大量データを活用していた。
2000年代に入ってから、専用のハードウェアにより大幅な性能向上を実現させたDWH専用のアプライアンスが登場したが、SNSなどで大量に発生するログデータを処理するために、さらなる性能向上のニーズが高まった。
これに対応するため、マスターノードの役割を固定しない超並列処理と、処理に必要な列だけを扱う列(カラム)指向のアーキテクチャを実装した新型DWH向けRDBMSが登場した。超並列処理はデータ量に応じたスケールアウトを可能とし、列指向技術はデータ圧縮技術と組み合わせることで、I/O処理の削減とメモリの有効活用により性能向上を実現している。
これらのニーズに応えるために、日本ユニシスでも2013年から、超並列処理と列指向技術を採用したHewlett Packard EnterpriseのHP Vertica Analytics Platform(以下、Vertica)を新型DWH向けRDBMS製品として販売開始した。
Hadoopの技術動向
Hadoopは、並列処理を行うためのオープンソースミドルウェアである。並列処理は、ひとつの計算処理を分割し、複数のサーバーで並列に処理することにより処理時間を短縮する技術である。2003年と2004年にGoogleが発表した並列処理に関する二つの論文「The Google File System」、「MapReduce: Simplified Data Processing on Large Clusters」を参考に、Doug Cuttingを中心とする少数のメンバーにより開発が始まり、Apacheコミュニティのプロジェクトとして、現在も多数の開発者により日々開発が進められている。
Hadoopは「HDFS(Hadoop Distributed File System)」と「MapReduce」の二つの主要技術から構成される。HDFSは、大容量のファイルを複数のサーバーに分割して格納する分散ファイルシステムである。MapReduceは、並列処理を行うJavaのフレームワーク/実行エンジンである。これらの技術により、大容量ファイル処理の時間短縮を実現している。
並列処理の技術は、スーパーコンピュータで採用されている標準規格のMPI(Message Passing Interface)などHadoop以外にも存在する。それらとHadoopが大きく異なる点は耐障害性がフレームワークとして備わっている点である。Hadoopは安価なコモディティサーバーで動かすことを想定して開発されており、ハードウェア故障が発生することを前提としたアーキテクチャになっている。
障害時にデータを欠損しないように、データの複製を別のサーバーに格納する。並列処理の途中でサーバーの障害が起きた場合には、行っていた処理を別のサーバーで自動的にやり直す仕組みが備わっている。そのため、利用者は障害発生時の考慮を意識することなく、ビジネスロジックの実装に専念できることから、ビッグデータの蓄積/処理基盤として注目を集めている。
Hadoopの利用が進むにつれて、より多くの人が利用できるように周辺での機能拡張が行われている。それら機能拡張のコンポーネントはHadoopエコシステムと呼ばれる。例えば、Javaで実装する必要があったMapReduceを、SQLに似た言語で扱えるようにしたHiveがその代表である。さらに、標準SQLへの準拠度を上げ、対話型の処理を行うために、SQL on Hadoopも登場しており、その一つにDrillがある。Drillは、MapReduceを用いずにメモリで処理を行うことにより、処理速度を向上させている。
また、技術力を持った先進的な企業でなくとも安心して使えるように商用ディストリビューションが提供されている。代表的なベンダはCloudera、Hortonworks、MapR Technologiesである。日本ユニシスでは2014年から、MapR TechnologiesのHadoopディストリビューション(以下、MapR)を販売開始した。MapRでは、I/O効率を向上させ、NFS(Network File System)でのアクセスを可能にしたHDFS互換の独自ファイルシステム(以下、MapR-FS)を採用している。
SQL on Hadoopの適用範囲についての仮説と検証環境
SQL on Hadoopの適用範囲についての仮説
SQL on Hadoopの適用範囲について3つの性能の観点で仮説を検討する。1つ目は検索するデータを取り込む時間、2つ目はデータを検索する時間、3つ目は同時アクセスでの検索時間である。データ取り込みについては、HadoopはDWH向けRDBMSに比べ処理時間は短い。これはDWH向けRDBMSで、検索処理を速くするようなデータの並び替えやフォーマット変換などを取り込み時に行っているためである。検索処理については、データ取り込み時に独自フォーマットで格納しているDWH向けRDBMSの処理時間が一番短く、メモリで処理を行っているSQL on Hadoopは、MapReduceで処理を行うHiveに比べて処理時間が短い。同時アクセスについては、DWH向けRDBMSはリソースを一元的に管理することによって効率的にデータ共有を行っているため、Hadoopに比べて同時実行性能は高い。
以上のことから、以下の仮説が考えられる。これらの仮説は次項で検証している。
(仮説1)Hadoopは、分析対象となる全てのデータの格納に向いている。
(仮説2)DWH向けRDBMSは、利用頻度が高いデータに絞り込んで格納する必要がある。
(仮説3)SQL on Hadoopは、対話型による試行錯誤的なデータ検索に向いている。
(仮説4)Hiveは、メモリサイズ以上の大量データを扱うバッチ処理に向いている。
(仮説5)DWH向けRDBMSは、多くの利用者が同時にアクセスするデータ検索に向いている。
したがって、SQL on Hadoopの適用範囲は図1のように、Hadoop(データレイク)内のデータに対する対話型の検索ツールとして有用であると考える。
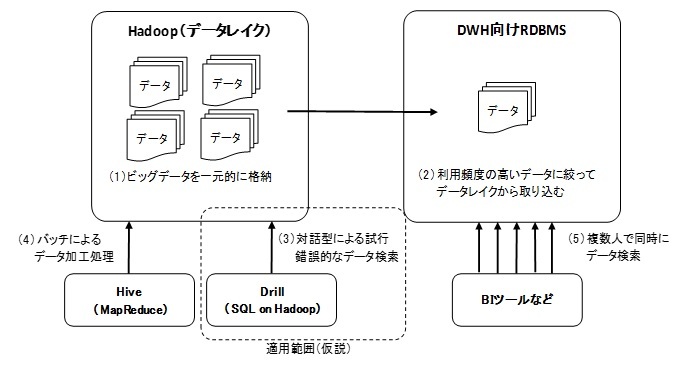 (図1)
(図1)拡大画像表示
検証項目
前節で挙げた仮説を検証するため表1のように、データロードとデータ検索における単独実行と同時実行について検証する。データ検索の実行クエリは、データ分析で基本となるグループ集計とテーブル結合のクエリとする。
 (表1)
(表1)拡大画像表示