マイクロサービス、RPA、デジタルツイン、AMP……。数え切れないほどの新しい思想やアーキテクチャ、技術等々に関するIT用語が、生まれては消え、またときに息を吹き返しています。メディア露出が増えれば何となくわかっているような気になって、でも実はモヤッとしていて、美味しそうな圏外なようなキーワードたちの数々を「それってウチに影響あるんだっけ?」という視点で分解してみたいと思います。今回はビッグデータやアナリティクス、ストレージの分野で最近よく聞く「データレイク」を取り上げます。
【用語】データレイク
意思決定に必要なデータの見極めがますます困難なビッグデータ時代の救世主として、「データレイク(Data Lake)」が注目されています。発生したままの姿で支流から流れ込むデータを魚にたとえ、多様なユーザーが、誰でも簡単かつ迅速、そして安全に、自分のニーズに合わせて自在に探し扱えるように泳がせておく「データの湖」というイメージです。
デジタル改革の波が本格化し、ビジネスが活用すべきデータの量と種類が急増しています。業務システム上のデータ、IoT、自社サイトやEC、SNSのログ、オープンデータ、そして今後本格化が見込まれる企業間取引で得られる社外データ等々、文字どおりのビッグデータ時代が本格的に到来しています。
それらは、RDBMSや業務システムで扱う構造化データもあれば、画像や動画、音声、SNS投稿やメールといった非構造化データなど、姿も実に多様です。データレイクが目指すのは、こうしたあらゆるタイプのデータを、一部専門家だけでなく、R&D、営業、製造などの部門メンバー、そして人だけではなくシステムも、スマートにデータを扱い活用できるデータマネジメント基盤を指しています。
社内ユーザーのセルフサービスによるデータ発見、活用を促すデータ資産の持ち方として、Gartner、McKinsey、Amazonなど各社が提唱しています。IBMはより高度なデータ管理基盤の概念として、データリザヴァー(Data Reservoir : データの貯水池)の表現も使っています。
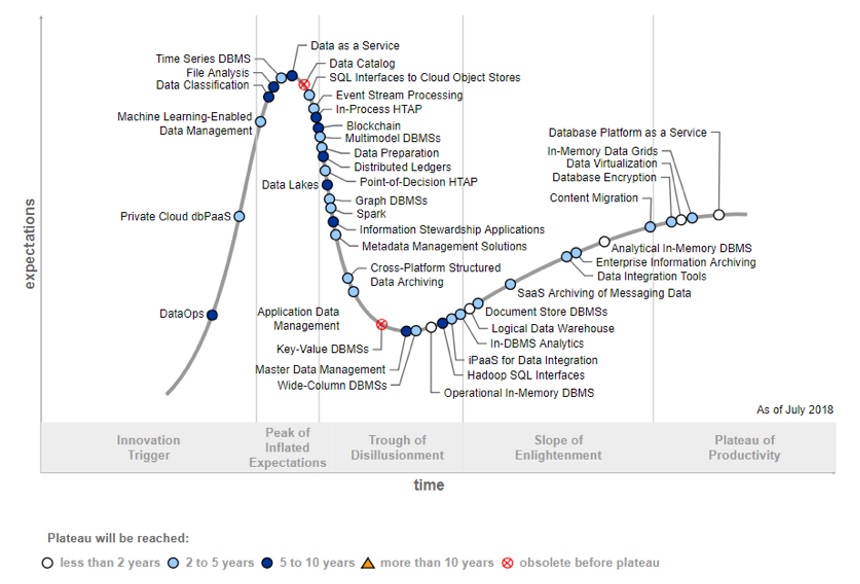 図1:Gartnerは流行期から幻滅期への移行段階に位置づける(出典:米ガートナー)
図1:Gartnerは流行期から幻滅期への移行段階に位置づける(出典:米ガートナー)拡大画像表示
【イノベーション】あらゆるデータをそのままの状態で蓄積
データレイクは、量、形式、実在する場所、管理者に関わらず、あらゆるデータを蓄積・管理し、ユーザーに応じた検索・分析をセルフサービス化します。湖へ支流が流れ込むように、発生したままの形式のあらゆる構造化/非構造化データ(ネイティブデータ)をまるごと、基本的にはリアルタイムで取り込みます。データウェアハウス等と異なり事前にデータ構造や取得元を設計しておく必要がなく、用途が決まっていないけれど使えそうなデータも取り込めます。
クレンジングやインデクシングといった前処理はあとまわしにして、まずは蓄積を優先します(やらなくてよいということではありません)。ネイティブデータをそのままの姿で保存することにより、データの鮮度を確保し、データの発生源からデータ活用ユーザーに至るデータパイプラインの最適化を図ります。
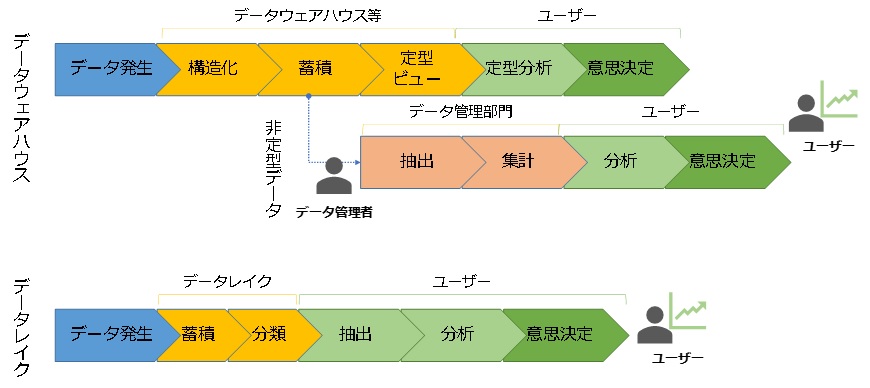 図2:データウェアハウス(上)とデータレイク(下)のイメージ:データウェアハウス上の構造化データまたは人手で抽出・集計したデータしか選択肢がなかったが、構造化されていないデータもタイムリーに分析できる
図2:データウェアハウス(上)とデータレイク(下)のイメージ:データウェアハウス上の構造化データまたは人手で抽出・集計したデータしか選択肢がなかったが、構造化されていないデータもタイムリーに分析できる拡大画像表示
データが物理ストレージに集約されている必要はなく、むしろ参照によって発生場所からデータを「移動させない」仕組みが好まれます。非定型のデータがほしいといったユーザーの要請に応えるデータマネジメント部門の個別対応をなくす効果も期待されています。
データウェアハウスやデータマートは、基本的にデータを扱うスキルを持つ担当者があらかじめ用途を決め、整形した構造化データとBIなどによる定型ビューを提供します。
一方、データレイクではビッグデータの蓄積も抽出、分析もセルフサービス。あらゆるユーザーがデータオーナーになり得ます。多くのデータレイクソリューションでは「サンドボックス(砂場)」と呼ばれるユーザー専用の分析スペースが用意され、IT部門やデータオーナーに負担をかけることなく、自身が使い慣れた分析ツールで、自由なビューによって分析や意思決定にデータを活用できます。データ活用のための事前処理を極力削減した、増大し多様化するデータユーザーの業務目的に合わせた管理・流通も担うデータ基盤と言えます。
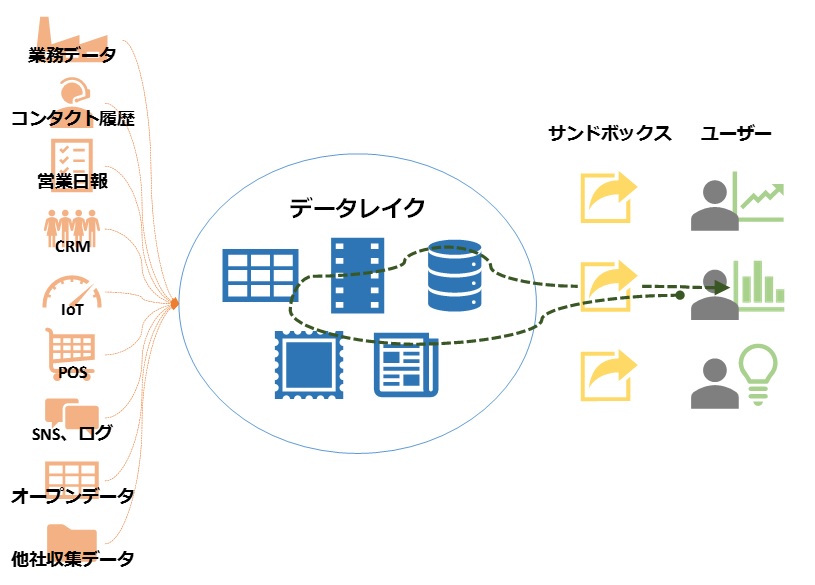 図3:データレイクのイメージ:様々なシーンで発生したままの形式でデータを蓄積。CxO、データサイエンティスト、事業部門などあらゆるユーザーが、それぞれのニーズに合わせて同時にデータを発見し、自分に合ったツールで活用できる
図3:データレイクのイメージ:様々なシーンで発生したままの形式でデータを蓄積。CxO、データサイエンティスト、事業部門などあらゆるユーザーが、それぞれのニーズに合わせて同時にデータを発見し、自分に合ったツールで活用できる拡大画像表示
「データカタログ」で「データスワンプ」を避ける
もちろん、ただ放り込んだだけのデータでは検索や加工に手間がかかったり、データの精度や信頼性を担保できなかったりといった課題があり、そうした状態はデータレイクとの対比で「データスワンプ(Data Swamp:データの沼地)」と呼ばれています。これではせっかくのビッグデータが、ユーザーに発見すらされません。
「沼」ではなくいつでも魚が捕れる「湖」を維持するために不可欠なのが「データカタログ」です。蓄積や更新の際データそれぞれにタイトルや概要、出どころ、鮮度やファイル形式といったメタデータを付与する手法が一般的で、ユーザーはこのカタログからデータを発見、抽出します。またデータレイクを標榜するIBMやMicrosoft、Informaticaといったベンダーのソリューションは、それぞれデータカタログの自動生成機能が備わっています。
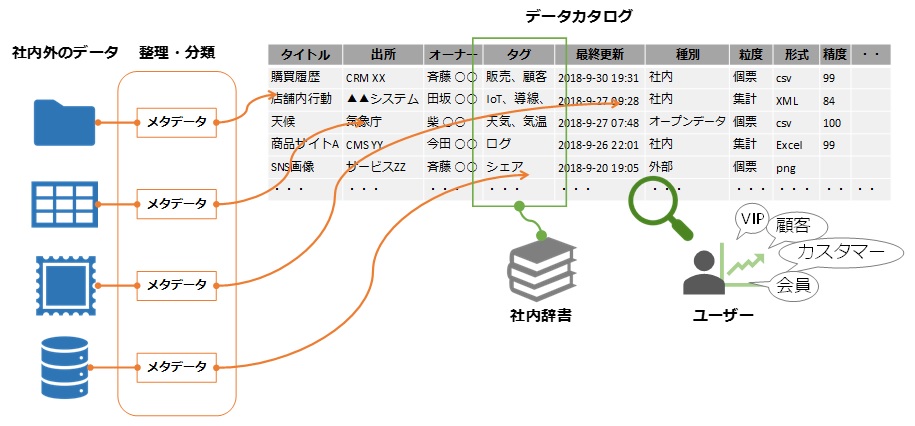 図4:データの整理整頓:内外のデータにメタデータ(書誌情報)を付与し整理・分類することにより、ユーザーが安心してセフルサービスでデータを検索、取得できる。検索性担保には社内辞書の構築が有効
図4:データの整理整頓:内外のデータにメタデータ(書誌情報)を付与し整理・分類することにより、ユーザーが安心してセフルサービスでデータを検索、取得できる。検索性担保には社内辞書の構築が有効拡大画像表示
【背景】拡大・多様化するデータ活用ニーズへの解
データレイクが注目される背景は、世界中で進むデジタルトランスフォーメーションに伴う、扱うデータの量、種類、トラフィック、そしてユーザーの激変です。
「フォグコンピューティング」の項で紹介したとおり、全世界のIPトラフィックは2016年の時点で年間1.2ZB(1.2ゼタバイト=13億テラバイト)に達します。また常時接続やAPIにより新たなトラフィックも増え、データ発生源であるデバイスやユーザーへの指示といった双方向の流れも生じました。内外のあらゆる部署で生まれ入手されたデータを、資産として一元管理するストレージが求められる所以です。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- 注目の秘密計算とは? プライバシー強化技術の実用レベルを確認する(2022/02/25)
- デジタル社会が求める「トラスト」の具体像─変わりゆくインターネットの「信頼」[後編](2021/06/14)
- デジタル社会の「トラスト」とは? 日本発「Trusted Web」構想を読み解く[前編](2021/05/18)
- 「情報銀行」を信用して大丈夫? 先行する海外活用動向と普及を阻む課題(後編)(2019/10/24)
- パーソナルデータが資産に?「情報銀行」の仕組みとビジネス環境(前編)(2019/10/10)





















